
Úmyslně překroucené citace o vzniku nové funkční genetické informace
Z www.discovery.org přeložil M. T. – 12/2010. Článek byl zpracován na základě příspěvků uveřejněných původně v Evolution News and Views.
Úvod Pavel Kábrt):
1. Tento článek byl uveřejněn na stránkách Discovery Institute, což je společnost vědců v USA známých pod označením ID – Intelligent Design (Inteligentní plán). Tito vědci se nezabývají dokazováním biblických událostí (např. potopou) jako klasičtí (ortodoxní či fundamentální) kreacionisté, ani datováním (je-li svět mladý či starý), ale vystupují hlavně proti darwinistické víře, že „mutace (atd.)+selekce (atd.)+milióny let (atd.)=současná živá příroda (atd.)“.
K vědcům ID patří např. známý Michael Behe (Darwinova černá skříňka aj.), Phillip Johnson (Spor o Darwina aj.), Charles Thaxton (Tajemství vzniku života aj.) či Jonathan Wells (Ikony evoluce aj.) a další vědci. 22. října 2005 měli tito vědci kongres v Praze. Oproti původním plánům se tohoto kongresu neúčastnil Michael Behe, protože byl právě svědčit v Doveru v soudním procesu Kitzmiller versus Dover.
2. Soudní proces Kitzmiller vs. Dover: Na podzim roku 2005 obžalovali rodiče 11ti studentů v Doveru (Pennsylvania, USA) oblastní vedení středních a základních škol z toho, že svým rozhodnutím uvádět při vyučování evoluční teorie také druhou možnost – stvoření, porušují ústavu USA. Soudní proces, probíhající bezmála dva měsíce, ve kterém stáli proti sobě vědci z řad evolucionistů a kreacionistů směru ID, a který vzbudil velkou mediální pozornost v USA, řídil vrchní soudce John E. Jones, který nakonec rozhodl ve prospěch evolucionistů; zakázal na státních školách v Doveru a přidružené oblasti deklarovat vedle evoluční teorie v hodinách biologie také teorii o stvoření, jako jednu z dalších možností vzniku přírody. Soudní spor se z velké části točil kolem otázky, zda je prokázané, že nová genetická informace může vzniknout darwinistickými procesy.
3. NCSE (National Center for Science Education) je nezisková organizace se sídlem v Kalifornii, USA, propojená s American Association for the Advancement of Science. Ve Spojených státech jde o hlavní protikreacionistickou organizaci, jejímž záměrem je bránit a propagovat vyučování evoluční teorie na státních školách.
I. Zavádějící scénář soudce Jonese
Nedlouho před začátkem procesu Kitzmiller v. Dover roku 2005 řekl člen tehdejšího Národního střediska pro vzdělávání ve vědě (NCSE) Nicholas Matzke jednomu reportérovi, že “Původ genetické informace je dobře znám” (1). V průběhu procesu pak navrhovatelův znalec, biolog Kenneth Miller, vypověděl, že předložil soudci Johnu E. Jonesovi “více než tři tucty vědeckých studií dokládajících, že nová genetická informace vzniká procesem evoluce” (2). Právním zástupcům navrhovatele se ve spolupráci s NCSE nakonec podařilo přimět soudce Jonese k papouškování Millerových slov; Jones ve svém verdiktu v případu Kitzmiller v. Dover totiž konstatoval, že Miller “poukázal na více než tři tucty uznávaných vědeckých publikací prokazujících původ nové genetické informace evolučními procesy” (3).
Prakticky všechny “publikace” zmíněné soudcem Jonesem pocházely z jediného článku probíraného Millerem během procesu: z jeho recenze vypracované spolu s Manyuanem Longem z chicagské university (4). V článku se přitom ani jednou nevyskytuje slovo “informace”, tím méně obrat “nová genetická informace” (5).
NCSE pak pokračuje ve své argumentaci citováním Longa et al. tvrdících, že o původu nové funkční biologické informace již dávno víme všechno. Roku 2008 zveřejnilo NCSE online odpověď na části knihy Zkoumání evoluce: argumenty pro a proti neodarwinizmu, ve kterých tvrdí, že “biologové nám mohou snadno demonstrovat, jak vzniká nová informace (chápaná podle definice specialistů v oboru její teorie) i jak se vyvíjejí nové geny či různé typy buněk a tkání.” Podobná konstatování se objevují v článku, jehož spoluautorem je dřívější pracovník NCSE Matzke, a který kritizuje kritickou analýzu evoluce. Matzke spolu s Paulem Grossem píší, že “je prostě ostudné” tvrdit, že moderní evoluční biologie má potíže s vysvětlením původu nové biologické informace, protože “kompetentní vědci vědí, jak vzniká nová genetická informace” (6). I on se opírá o článek Longa et al. a tvrdí, že “podává přehled všech mutačních procesů účastnících se vzniku nových genů, a pak uvádí celou řadu příkladů prací, ve kterých výzkumné týmy dokladují původ různých genů” (7).
Jsou však odvážné proklamace soudce Jonese, Kena Millera i NCSE podložené? Odhaluje Long et al. skutečně původ nové biologické informace? Mýlí se kniha Zkoumání evoluce? Při bližším zkoumání celé problematiky ovšem zjistíme, že NCSE vlastně zamlžuje smysl slov “informace” a “nový” a že citáty, kterými se ohání, jsou do značné míry blafy říkající nám pramálo o tom, jak by nová genetická informace mohla vznikat neřízenými evolučními mechanizmy. A soudce Jones jim tento blaf “zbaštil i s navijákem” a postavil na tom své krajně mylné rozhodnutí.
Však je také původ nové funkční biologické informace snad nejdůležitější otázkou v biologii. Jak zdůraznil badatel na poli původu života Bernd-Olaf Kuppers ve své knize Informace a původ života, “Problém původu života je jednoznačně v zásadě rovnocenný problému původu biologické informace” /8/.
Soudce Jones nebyl přitom pouze na omylu. Jeho rozhodnutí neznamenalo pouze selhání v samotném soudním případu, ale blud, který obsahovalo, se rozšířil do médií i akademické kultury, etabloval se jako darwinovský mýtus po boku mýtů podobných. Tenhle mýtus říká, že snad nejdůležitější otázka v biologii byla vyřešena, i když ve skutečnosti (jak ukážeme v tomhle článku) tomu zdaleka tak není.
II. Nepoužitelná definice biologické informace podle evolucionistické lobby
Aby mohli NCSE/Ken Miller/soudce Jones tvrdit, že “vznik nové genetické informace lze vysvětlit evolučními procesy”, museli zamlžit jak definici slova “informace” tak slova “nový”. V souladu s NCSE by soudce Jones patrně definoval informaci pouze jako “Shannonovu informaci”, tj. pouze jako cosi složitého. Podle téhle definice by nefunkční úsek náhodně “nakupené” odpadové DNA disponoval týmž množstvím “informace” jako plně funkční gen o téže délce sekvence. Vyjádříme-li tedy informaci v pojmu Shannonovy informace (což je prý podle NCSE “význam užívaný informatiky”), pak budou následující dva řetězce obsahovat stejné množství informace:
Řetězec A:
SHANNONOVOUINFORMACÍNEJDEVYJADŘOVATBIOLOGICKÁSLOŽITOST
Řetězec B:
HANOICOVYOINONMCÍSNDSEVAJAŽDOVTABIUOLGFORŘKÁEJSLOITOTN
- (shannon, zn. Sh = jednotka množství informace; množství informace získané přijmutím jednoho prvku dvouprvkové abecedy, jestliže výskyt každého prvku má stejnou pravděpodobnost. Užívá se např. při vyjadřování průměrného množství informace připadající na jeden prvek abecedy zdroje. Pozn. překl.)
Jak řetězec A tak řetězec B tvoří přesně 54 písmen a oba řetězce mají přesně týž objem informace vyjádřený v shannonech – zhruba 254 bitů (9). Jisté však je, že řetězec A nám sděluje mnohem více funkční informace než řetězec B, který vznikl pomocí generátoru písmen pracujícího na principu náhodného výběru (10). Je tedy nasnadě, že složitost systému vyjadřovaná v shannonech je již dlouho kritizována jako nepoužitelná měrná jednotka pro funkční biologickou informaci. Biologická informace je totiž především cosi mnohem citlivěji nastaveného – tak, aby to mohlo plnit specifickou biologickou funkci -, zatímco u řetězců náhodných tomu tak není. Využitelné měřítko pro biologickou informaci musí především vysvětlit funkci informace, což Shannonova informace nebere v potaz.
Někteří čelní teoretikové zmíněnou problematiku reflektují. Roku 2003 si badatel zabývající se vznikem života a nositel Nobelovy ceny Jack Szostak v jedné recenzi v časopisu Nature postěžoval, že problémem „klasické teorie informace“ je fakt, že se prostě „nezamýšlí nad smyslem sdělení“ a místo toho definuje informaci „jako pouhý nástroj k vymezení, skladování či přepisu příslušného řetězce DNA“ (11). Podle Szostaka „potřebujeme novou měrnou jednotku pro informaci – funkční informaci“, abychom byli s to zohlednit schopnost dané proteinové sekvence plnit danou funkci. V témž tónu poznamenává jeden článek v časopisu Teoretická biologie a medicínské modelování:
- „Ani RSC (míra složitosti náhodné sekvence) ani OSC (míra složitosti sekvence uspořádané) ani kterákoli kombinace zmíněných dvou veličin nestačí k popisu složitosti funkcí pozorovaných u živých organizmů, neboť ani jedna nezohledňuje rozměr funkční vitality, který je tu navíc – a právě ten činí život životem. FSC (míra složitosti funkční sekvence) tento rozměr zahrnuje. Szostak tvrdil, že nám nestačí ani původní měrná jednotka pro neurčitost vyjadřovaná v shannonech ani měrná jednotka pro algoritmickou složitost. Klasická informační teorie pracující se shannony nezohledňuje smysl čili funkci sdělení. Složitost vyjádřená pomocí algoritmů není s to vysvětlit náš poznatek, že ‚různé molekulární struktury mohou mít tutéž funkci.‘ Z tohoto důvodu upozorňoval Szostak, že potřebujeme novou měrnou jednotku pro informaci – informaci funkční“ (12).
Roku 2007 zveřejnil Szostak spolu s badatelem v oblasti původu života z Carnegieho nadace Robertem Hazenem a dalšími vědci v časopisu Proceedings of the National Academy of Sciences (Zprávy Národní akademie věd) článek dále rozvádějící tyhle problémy. Po kritice těch, kdo trvají na měření biologické složitosti zastaralými metodami využívajícími jako měrné jednotky pro informaci shannony autoři pokračují: „Složitost neprostudujeme řádně do té doby, než koncepční rámec a předpovědní potenciál její případné měrné jednotky nebudou založeny na hlubším porozumění chování složitých systémů.“ Tihle vědci tedy „navrhují měřit složitost systému v pojmech funkční informace, tedy informace nutné k zakódování specifické funkce“ (13).
Také Stephen C. Meyer se drží tohohle přístupu, když píše v jednom peer-reviewed vědeckém článku, že by snad bylo dobré zavést pojem „‘informace specifické složitosti‘ (CSI) jako synonymum pro ‚vymezenou složitost‘, abychom dokázali rozlišovat mezi funkční biologickou informací a pouhou informací vyjádřenou v shannonech – tedy mezi vymezenou složitostí a složitostí jako takovou“ (14). Meyerem navrhovaná definice „specifické složitosti“ nám může pomoci popsat funkční biologickou informaci. Specifická složitost je konceptem vycházejícím ze standardní vědecké literatury – není tedy vynálezem kritiků neodarwinizmu. Už roku 1973 charakterizoval badatel na poli vzniku života Leslie Orgel specifickou složitost jako určující znak složitosti biologické:
- „Živé organizmy charakterizuje specifická složitost. Krystaly považujeme obvykle za prototypy jednoduchých, dobře rozeznatelných struktur, protože je tvoří velmi značné množství standardním způsobem nakumulovaných stejných molekul. Žulové úlomky či náhodné směsi polymerů jsou příklady struktur, které jsou složité, nikoli však specifické. Krystaly nemůžeme považovat za živé, protože postrádají složitost; směsím polymerů chybí zase k tomu, abychom je mohli pokládat za živé, specifita (tj. vymezenost, charakteristická, jedinečná složitost – poz. edit.) (15).
Orgel tak vystihuje skutečnost, že k tomu, aby někde mohla existovat specifická složitost čili CSI, musí být přítomna jak nepravděpodobná sekvence, tak specifické funkční uspořádání. Specifická složitost je mnohem lepší měrnou jednotkou biologické složitosti než informace vyjádřená v shannonech; tuhle skutečnost ovšem nemůže NCSE „vydýchat“, protože je mnohem těžší vygenerovat darwinovskými procesy složitost specifickou než pouhou složitost vyjádřenou v shannonech.
Svým tvrdošíjným trváním na teorii, podle které pouze informace vyjádřená v shannonech „může podle informatiků mít smysl“ se NCSE vyhýbá odpovědím na těžší otázky jako je problém procesu, kterým se informace v biologických systémech stává funkční, či jeho vlastními slovy, „užitečnou“. Spíše se zdá, že NCSE záleží víc na řešení povrchně zjednodušujících, triviálních otázek, jako je problém přidávání eventuálních dalších písmen k řetězci DNA či jeho zdvojování, bez ohledu na podstatnou otázku toho, zda ponesou ona další písmena nějaké nové fungující sdělení. Jelikož je biologie založena právě na takové fungující informaci, zajímá darwinoskeptiky daleko důležitější problém, totiž zda umí neodarwinizmus vysvětlit, jak vzniká nová fungující biologická informace.
III. Mylná definice pojmu „nový“ u evolucionistické lobby
Když soudce Jones prohlásil, že Ken Miller prokázal „že nová genetická informace vzniká evolucí“, bylo to proto, že ve svých posudcích Ken Miller a jeho druzi z NCSE nezamlžili pouze pojem „informace“, nýbrž že zneužili pro své cíle i pojmu „nová“. Tihle lidé by totiž byli schopni přijmout za „novou informaci“ i pouhou kopii či dvojníka nějakého již existujícího řetězce DNA, i kdyby taková „nová“ kopie vlastně ničím novým nebyla či snad dokonce i tehdy, kdyby nebyla nová DNA vůbec k ničemu. Na rozdíl od nich definují zastánci inteligentního plánu „novou“ genetickou informaci jako nový řetězec DNA plnící skutečně nějakou odlišnou, smysluplnou a novou funkci. Vezměme si například tento řetězec:
ZDVOJENÍTOHOTOŘETĚZCENEVEDEKEVZNIKUNOVÉCSI
Tento řetězec o 42 písmenech má ~ 197 bitů informace vyjádřené v shannonech. Nyní se podívejme na následující delší řetězec:
ZDVOJENÍTOHOTOŘETĚZCENEVEDEKEVZNIKUNOVÉCSI ZDVOJENÍTOHOTOŘETĚZCENEVEDEKEVZNIKUNOVÉCSI
Tahle procedura prostě přidala do textu 42 „nových“ písmen, ale nevznikla žádná nová funkce. Přijmeme-li postulát, že nebylo možno předpovědět předem, že dojde právě k takovémuhle zdvojení prvého řetězce, pak se množství informace vyjádřené v shannonech opravdu zdvojnásobilo; množství CSI však nevzrostlo ani o bit (doslova).
Shora uvedeným příkladem lze samozřejmě ilustrovat mechanizmus genové duplikace, jak ho běžně chápou evolucionisté; prý tak podle nich mohou darwinovské procesy vytvořit novou informaci. Nová fungující informace však nevznikne duplikací řetězce DNA, dokud mutace nezmění gen natolik, aby vygeneroval novou funkci – což je či možná není v jeho silách. Dobře to řekl profesor neurochirurgie Michael Egnor v reakci na tvrzení jistého evolučního biologa:
- „Genovou duplikaci nelze podle všeho brát příliš vážně. Budete-li považovat pouhé kopie za novou informaci, pak při výuce můžete jen těžko kritizovat fakt, že nějaký student něco od kolegy opsal. Vše, co by na to za takovéto situace nezvedení študáci asi řekli, by bylo: ‚Vždyť je to jako s genovou duplikací! Můj plagiát je nová informace – napsal jste to přece ve svém blogu!‘ “ (16).
Evolucionisté proto ve svých interpretacích vzniku biologické informace nemohou prostě vystačit s pouhou duplikací řetězce DNA, neboť ta by musela přinést kódovanému subjektu novou funkci – jinak evoluce není možná (17).
IV. Za všemi průšvihy vězí Darwin
Zastánci neodarwinizmu sice prohlašují, že rozumějí tomu, jak vzniká nová genetická informace, ve skutečnosti však svými vágními formulacemi „genová duplikace“, „přeskupení“, „přírodní výběr“ jen zamlžují skutečnost, že žádné vysvětlení pro zmíněný proces nemají. Tyto mechanizmy jsou obecně odvozovány z nahodilých faktů, jako jsou podobnosti a rozdíly mezi genovými sekvencemi, kde se automaticky předpokládá neodarwinovská historie. A co hlavně, výklady, které používají shora uvedené pojmy, se téměř nikdy nepokoušejí stanovit pravděpodobnost výskytu mutací odpovědných za diskutované genetické změny. Proto se doporučuje obezřetnost, když evolucionista vykládá původ genu.
Evoluční biolog Michael Lynch jde ve svém článku z roku 2007 v časopisu Proceedings of the National Academy of Sciences USA ke kořenům některých předpokladů stojících za mnoha tvrzeními neodarwinovské evoluce. Lynch vypočítává mýty rozšiřované biology, přičemž nazývá „mýtem“ jejich přesvědčení, že „Popis interspecifických rozdílů na molekulární a/nebo buněčné úrovni se rovná nalezení mechanizmů evoluce“ (18).
Jedním z typických „mechanizmů evoluce“ zmíněných v předchozím odstavci je pak samozřejmě přírodní výběr považovaný běžně za rozhodující faktor v procesu, kterým duplikát genu získává novou funkci. Jak závažný důkaz je však třeba podat, aby se prokázalo, že k pozitivnímu neboli přírodnímu výběru sloužícímu k fixaci adaptivních mutací skutečně došlo? Biolog Austin Hughes varuje, že většina hypotéz pracujících s pozitivním výběrem je založena na sporných statistických analýzách genů:
- „Velkou překážkou poznání v téhle oblasti je zmatek kolem role pozitivního (darwinovského) výběru, tj. přírodního výběru upřednostňujícího adaptivní mutace. Problémy činí zejména všeobecné užívání jistých špatně koncipovaných statistických metod při ověřování, zda v konkrétním případě proběhl pozitivní výběr. Každý rok zveřejní vědci tisíce článků přinášejících údajně důkazy o adaptivní evoluci opírající se výhradně o počítačové analýzy bez jakékoli vazby s důsledky údajných adaptivních mutací pro fenotyp….V rozporu se všeobecně rozšířenou představou nezanechává přírodní výběr v genomu žádnou jednoznačnou „stopu“, rozhodně ne takovou, aby ji bylo možno zjistit po desítkách či stovkách milionů let. Pro biology vzdělávané v duchu neodarwinizmu je však prakticky axiomem, že všechny adaptivní změny se v organizmu zafixují jako výsledek přírodního výběru. Je však důležité si uvědomit, že realita může být komplikovanější než zjednodušené učebnicové scénáře. …V poslední době zaplavují literaturu evoluční biologie extravagantní tvrzení o pozitivním výběru, založená výhradně na počítačových analýzách…Tahle přehršel pseudodarwinovských nepodložených hypotéz bytostně poškozuje důvěryhodnost evoluční biologie jako vědy (19).
Krátce řečeno, evoluční biologové většinou předpokládají, že přírodní výběr zafixoval mutace měnící proteinové sekvence; tato domněnka však zřejmě neobstojí, jelikož mnohé takové mutace jsou neutrální a nenesou s sebou žádnou selekční výhodu.
Biochemik Michael Behe uvádí další důvod, proč vědci nemají počítat s neodarwinistickými mechanizmy změn, které se zračí pouze v podobnosti sekvencí:
- „Ačkoli nám to může pomáhat při stopování fylogenetických vztahů…nemůžeme ze srovnávání sekvencí poznat, jak získala složitá biochemická soustava funkci, kterou plní – otázka, která nás v téhle knize nejvíce zajímá. Na základě analogie mohou mít uživatelské příručky pro dva různé typy počítačů vyráběné stejnou společností mnoho totožných slov, vět a dokonce i celých odstavců svědčících o společném původu (možná že je obě napsal tentýž autor), srovnáním sledů písmen v nich však nikdy nedospějeme k jistotě o tom, zda můžeme počítač sestavit po krocích ze součástek psacího stroje…Podobně jako sekvenční analytici jsem i já přesvědčen o tom, že důkazy mluví celkem jasně pro původ ze společného předka. Zásadní otázka však zůstává nezodpovězena: Co způsobilo, že se v přírodě vyvinuly tak složité systémy?“ (20)
- „Moderní darwinisté uvádějí ve své argumentaci důkazy o původu ze společného předka a omylem je zaměňují za důkazy o síle náhodných mutací“ (21).
Mnoho vědeckých článků zaměřených na demonstraci evoluce „nové genetické informace“ se spokojí s tím, že prostě vyjmenují podobné i odlišné vlastnosti molekul již existujících genů, a pak se pustí do líčení evolucionistických pohádek o duplikacích, přeskupování a následném rozrůzňování znaků organizmů v průběhu fylogeneze jako důsledku přizpůsobování se rozdílným aktivitám či podmínkám prostředí – to vše opřené o vágní tvrzení o „pozitivní selekci“ -, které se snaží vysvětlit, jak ten který gen vznikl. Ve skutečnosti však nikdy takové vysvětlení nepodají. Prakticky nikdy se pak evolucionisté nezabývají otázkou, zda náhodné mutace a neřízený přírodní výběr postačí k tomu, aby vyprodukovaly relevantní genetické změny (22). Tyhle vědecké články – zejména blafy uvedené v odůvodnění rozsudku soudcem Jonesem a opřené o tvrzení NCSE i Kena Millera – hrají Hru na evoluci genů, oblbovačku, která nám vposledku řekne pramálo o původu nové funkční genetické informace, jak uvidíme v dalším odstavci.
V. Jak hrát hru „evoluce genů“
Hra na evoluci genů se hraje velmi snadno. Uvedeme tři příklady, ze kterých vyvodíme tři pravidla umožňující kdykoli vysvětlit původ kteréhokoli nového genu. Přesně tak – kteréhokoli genu! Začněme jednoduchým příkladem:
Pravidlo č. 1: Kouzelný proutek genové duplikace
Odkud pocházejí nové geny? Běžně to vědci vysvětlují genovou duplikací. A takhle to prý probíhá:
- Vezmi gen, který jsi pozoroval u nějakého organizmu. Nazveme ho gen B.
- Najdi jiný gen, který se bude podobat genu B. Nazvěme ho gen A.
- Předpokládejme, že se kdysi gen A zdvojil, takže existoval ve dvou exemplářích.
- Pak předpokládejme, že se z jednoho exempláře genu A vyvinul gen B.
Zdvojováním genů se tedy evoluce vysvětlí velmi snadno; můžeme ho znázornit takhle:
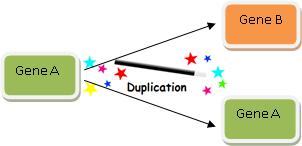
No, není to snadné? Právě jsme vysvětlili, jak se vyvinul gen B! Takže kdykoli se setkáte se dvěma geny s velmi podobnými sekvencemi, můžete vždy pomocí kouzelného proutku genové duplikace vysvětlit, jak se jeden vyvinul z druhého.

V materiálech NCSE se píše: „Genové duplikace jsou běžnými jevy vznikajícími z chybiček v procesu buněčné replikace. Jakmile se jednou gen zdvojil, může jedna kopie zmutovat a vytvořit novou informaci, aniž by ohrozila svou funkčnost.“ Tohle je tedy celý ten fígl – předpokládáte-li, že dochází ke zdvojování genů, máte jasno i v tom, že jakmile jeden z nich získá novou funkci, funguje prostě v procesu evoluce bez problémů dál. Jinými slovy, otázka vzniku nové funkční genetické informace je nedůležitá, protože vše potřebné vysvětlí „genové duplikace“! Vznik nové genetické informace v Shannonově smyslu je prostě snadný – tak kde je problém?
Pravidlo č. 2: Žádný strach – přírodní výběr to zvládne!
Je ovšem pravda, že naše moderní verze genu B není zcela totožná s genem A, protože jinak by byla genem A a nikoli genem B. Takže musíme vysvětlit, jak získala tahle kopie genu A novou funkci – funkci B. Bylo by nasnadě, že právě o tohle jde při snaze vysvětlit, jak vzniká nová funkční genetická informace, ale věřte tomu nebo ne, tohle je vlastně ten nejsnadnější a nejrychleji řešitelný problém v celé hře: přivoláme prostě na pomoc tvůrčí potenciál „přírodního výběru“ – a je to! Následující diagram popisuje přesně, jak to probíhá:
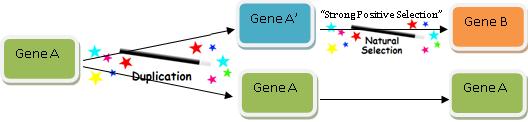
Vtipem hry s evolucí genů je fakt, že přírodní výběr dokáže změnit (či zachovat, podle toho, o co vám momentálně jde) téměř všechno. Říkám všechno.
O podrobnosti se nestarejte. Budete-li chtít vysvětlit rozdíly mezi genem B a genem A, můžete se vždy uchýlit k přírodnímu výběru. Klidně ignorujte skutečnost, zda se u genu A měnila funkce A na funkci B malými postupnými adaptivními krůčky. Nepřemýšlejte o pořadí, v jakém se měnily aminokyseliny, či zda bylo nutno mnoho mutací k tomu, aby se získala nějaká funkční výhoda (taková věc se velmi pravděpodobně stejně vůbec nestane, takže se na to prostě vykašlete). Rovněž si vůbec nic nedělejte z případných adaptivních omezení, nedostatku výběru nebo ztrát vinou genetického driftu. A především, ZA ŽÁDNÝCH OKOLNOSTÍ NEPROPOČÍTÁVEJTE PRAVDĚPODOBNOST výskytu všech těch dříve uvedených pozitivních změn během nějaké rozumné doby.
Víme, že gen se musel vyvinout, takže se prostě vyvinul a basta. Takže si můžete přírodní výběr představit jako takové mávnutí kouzelným proutkem. Je totiž připraven „zafungovat“ kdykoli, když musíte vysvětlit, jak se vlastně stalo, že se gen změnil či vyvinul a získal tak novou funkci.

Tahle kouzelná hůlka je nástrojem velice účinným – umí vysvětlit obojí: proč se věci mění, a proč se nemění. (23). Vau – fantastické!
Pravidlo č. 3: Kouzelný proutek „přeskupení“
Abyste mohli hrát hru na evoluci genů, musíte ovládat ještě poslední trik. Někdy se totiž gen B nepodobá jen genu A. Někdy se stane, že se mu podobá jen část genu B, zatímco jiná část genu B se podobá zase genu jinému. Nazvěme ho gen Z. Ale žádný strach – i tenhle jev se dá snadno vysvětlit! Začneme tím, že přivoláme na pomoc duplikaci: představte si, že se jak gen A tak Z zdvojily, a pak byly obě nové kopie najednou přemístěny v genomu tak, že teď se nalézají na chromozomu pěkně vedle sebe. Tenhle proces nazývají evolucionisté „přeskupením“. Připadá-li vám to poněkud komplikované, nakreslíme si pár diagramů, abychom si ukázali, jak to funguje:
Krok 1: gen A a gen Z se nalézají na různých místech, možná dokonce na odlišných chromozomech:
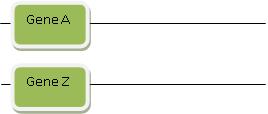
Potom zvláštní proces zvaný „přeskupení“ náhle genom přeorganizuje a dostane oba geny do bezprostřední blízkosti v nějakém jiném úseku genomu. Přeskupení je mocnou kouzelnou hůlkou, která je vám k dispozici vždy, když potřebujete vysvětlit, jak se dva původně vzdálené úseky DNA dostanou náhle těsně k sobě. Z tohohle spojení pak může vzniknout nový funkční gen. Takže už vám snad svítá, jak to funguje:

Existují všechna možná přeskupení, na která se můžete odvolat – inzerce, delece, inverze, translokace – a můžete si je představit prakticky v jakémkoli pořadí i rozsahu, které potřebujete, abyste dokázali vysvětlit, jak se přes celý genom integrují jakékoli dva, tři či dokonce tucty kousků DNA, takže natošup máte svůj nový funkční gen. Stačí jen po libosti namixovat a vhodně sestavit zmíněné druhy přeskupení a vytvoříte prakticky libovolnou sekvenci DNA – přeskupení je tu prostě pro vás kdykoli.

A dále už všechno jde jako po másle. Přírodní výběr se pak ujme své role a zdokonalí přeskupený gen, aby dobře fungoval. S podrobnou analýzou toho, zda tomu tak skutečně je, si prosím, nedělejte starosti. Okořeňte to prostě jen špetkou přírodního výběru a z kombinace funkcí genů A a Z se vyvine gen B. No a máme to, vše, co jsme chtěli vědět, víme:

S využitím zmíněných třech kouzelných proutků duplikace, přeskupení a přírodního výběru dospějete k dokonalému a podrobnému objasnění evoluce prakticky všech genů.
Nemůžete zjistit předchůdce? Žádný problém!
Za prvé, v některých případech je znám homolog vašeho genu (tj. genu B) pouze u zcela odlišného druhu. Takže jak se vlastně gen B do vašeho organizmu dostal? V těchto případech prostě povolejte na pomoc laterální přenos genů (LGT) a příslušný gen přistane ve vašem organizmu jako na létajícím koberci. Nezáleží přitom ani na tom, zda se připouští vznik laterálního přenosu genů právě mezi organizmy, se kterými pracujete – existuje-li gen, který potřebujete, u nějakého jiného organizmu, pak už tento pouhý fakt je důkazem toho, že laterální přenos genů mezi organizmy, se kterými pracujete, funguje! (24)
Za druhé, někdy se stane, že část vašeho genu vůbec neodpovídá části žádného známého genu. Někdo by se zeptal: „Kde se tu vlastně tenhle gen vzal?“ Jen zůstaňte nadále klidní. Vzpomínáte si, co jsme říkali o přírodním výběru? Dokáže změnit prostě všechno. Takže nemůžete-li najít geny podobné, jednoduše si řekněte, že díky přírodnímu výběru se vaše jedinečná sekvence DNA vyvinula natolik, že už se prostě své sekvenci výchozí v ničem nepodobá. Ale nemějte obavy, nějaký ten předek se vždycky dá vymyslet. Je to prostě tak, že mocná síla přírodního výběru změnila příslušný gen natolik, že nějaká výchozí sekvence už je prostě neidentifikovatelná (25).
Několik rad „co dělat“ a „co nedělat“ při hře na evoluci genů
V předešlém výkladu vás asi udivil náš poslední příklad. Takže než půjdeme dál, připomeňme si otázky, které nikdy nepokládejme:
- Známe-li efektivitu i četnost výskytu mutací, jaká je pravděpodobnost, že se geny A a Z octnou náhle díky přeskupení těsně vedle sebe, takže teď budou fungovat společně jako jediný nový genový produkt, gen B?
- Začal vůbec přeskupený genový produkt B fungovat? Není-li tomu tak, jak rychle by se tak mohlo stát? A jak byl zmíněný produkt zabezpečen před zničením, než začal fungovat?
- Jsou proteiny opravdu tak pružné, jak bychom předpokládali po vyslechnutí tohohle příběhu, či čeká na nově sestavený gen foulding (svinutí, složení) nebo jiné aktuální problémy?
- Jaká mutační cesta vedla k vývoji genů A a Z v nový gen s funkcí B?
- Jaké selektivní výhody s sebou nesly krůčky této evoluční cesty?
- Byly na zmíněné cestě někdy třeba nějaké „velké kroky“ (tj. vícenásobné specifické mutace), aby se dosáhlo selektivní výhody?
- Mohlo k tomu všemu dojít v rozumném časovém měřítku?
(folding – V biologii se tak označuje proces „skládání“ proteinu do terciární struktury. Pozn. překl.)
S podobnými otázkami si skutečně nemusíte lámat hlavu. Ve skutečnosti, věřte nebo nevěřte, nemusíte dokonce ani vědět, jakou funkci má váš gen, a přitom stejně můžete tvrdit, že se vyvinul z A a Z! Všechno, co vědět musíte, je to, že geny A, Z a B existují. Následující souhrn probraných 3 jednoduchých pravidel hry na evoluci genů vám pomůže vysvětlit PROSTĚ COKOLI:
Hra na evoluci genů – pravidlo č. 1: Kdykoli zjistíte sekvenční homologii mezi dvěma geny, postulujte prostě duplikační jev proběhnuvší u nějakého hypotetického dávného genu-předka a vysvětlíte tak, jak dva odlišné geny přišly k těmto společným prvkům.
Hra na evoluci genů – pravidlo č. 2: Máte-li vysvětlit, jak získal určitý gen nějakou novou funkci nebo jak se u něj vyvinuly prvky odlišné od genu jiného, sáhněte po kouzelném proutku přírodního výběru. Nemusíte přitom dokládat, že takto vzniklý nový gen znamená pro organizmus nějaký přínos nebo že organizmus po této změně nastoupil postupnou cestu přizpůsobení se. Konečně, přírodní výběr je zvlášť užitečný tam, kde se část vašeho genu jeví jako jedinečná – jelikož totiž přírodní výběr umí změnit naprosto cokoli, tvrďte prostě, že změnil váš gen natolik, že už se nepodobá svému předku.
Hra na evoluci genů – pravidlo č. 3: Jeví-li se gen jako skládačka prvků z genů několika, postulujte prostě duplikace i přeskupení libovolných sekvencí DNA, které se vám hodí, jen abyste je všechny shromáždili na správném místě. Potřebujete-li smazat části nějakého genu nebo je prohodit či přemístit jinam, postulujte prostě tak často a zcela dle libosti různé druhy přeskupení – a ejhle, máte svůj nový gen!
A pamatujte si, nikdy neklaďte žádné choulostivé otázky. Použijte prostě zmíněná tři pravidla a vysvětlíte pomocí nich prakticky všechno. Na podrobnosti se nikdo nebude ptát!
VI. Správné otázky ohledně evolučního původu nové biologické informace
Teď ale už vážně: v dosavadním výkladu jsme probírali, jak je snadné zdvojit gen; klíčovou chybějící informací, v mnoha neodarwinovských interpretacích původu nové genetické informace, je, jakou cestou získá kýžený genový duplikát nějakou novou optimalizovanou funkci. Evolucionisté kromě vzácných výjimek neprokázali, že existují souvislé řady „chytrých“ dílčích kroků vedoucí ke vzniku nové funkce.
Jak jsme také již výše probrali, varuje Austin Hughes před pronášením „kategorických tvrzení s platností důkazů, založených na počtu pravděpodobnosti, která absolutizují úlohu pozitivního výběru při vzniku nové informace a neberou přitom v potaz zúčastněné biologické mechanizmy“ (26). Jinými slovy, zmíněná tvrzení se dovolávají přírodního výběru, aby vysvětlila evoluci genů, a přitom ani neznáme mechanizmus fungování zkoumaných mutací. V této souvislosti Hughes poznamenává, že dokonce ani v jedné z propracovanějších studií zmíněné problematiky, která se mu dostala do ruky, „nenašel žádný přímý důkaz o tom, že by byl přírodní výběr opravdu zapojen do fixování adaptivních změn“ (27).
Hughes je si rovněž vědom problému, který je vlastní mnoha řešením argumentujícím přírodním výběrem, totiž že mutace, které taková řešení vyžadují, nemusejí při svém prvním výskytu přinést organizmu žádnou selekční výhodu. V jedné studii proto poznamenává:
- „Například rodopsin japonského úhořovce se schopností vnímat světlo o vlnové délce až maximálně 480 nm dosáhl téhle citlivosti díky souhře tří nových aminokyselin nahradivších ty bývalé (na lokusech 195, 195 a 292). Nevypadá to, že by přírodní výběr mohl těžit z jediné nové takto přemístěné aminokyseliny; adaptivní výhodu tak přináší až simultánní přemístění všech tří“ (28).
(rodopsin = zrakový pigment obsažený v tyčinkách sítnice. Je obsažen v membráně disků, kterých je v tyčince až 2000. Je tvořen bílkovinnou částí (opsinem) a částí aldehydickou (retinalem), která prodělává vlivem dopadu světla konformační změny. Rodopsin absorbuje světlo v celé oblasti viditelného světla s maximem u člověka okolo 505 nm. V tyčince je cca 100 milionů molekul rodopsinu. Součástí rodopsinu je vitamin A. Proto jedním z projevů vážnějšího nedostatku vitaminu A je tzv. šeroslepost (hemeralopie). Pigment je červený, proto je pojmenován po růži – řecky „rodo“ (pozn. překl.).
V tomhle případě tedy organizmus nezískával výhody postupně, s každou konkrétní mutací. A právě proto, že k nástupu výhody musely být přítomny všechny tři aminokyseliny, domnívá se Hughes, že je „rozumější“ předpokládat, že první dvě mutace byly prostě „selekčně neutrální“ a zafixovaly je tedy náhodné, neadaptivní procesy jako je genový drift (náhodné kolísání genových četností v populaci). Jakmile se pak objevila mutace třetí, získal možná organizmus skutečně výhodu, ale, abychom parafrázovali Scotta Gilberta, tenhle proces vysvětluje nanejvýš přežití nejzdatnějšího, nikoli to, jak se zde onen nejzdatnější vůbec objevil.
Hughesovo vysvětlení však stejně pořádně kulhá: postuluje třeba, že se dvě mutace zafixují ještě než je získána jakákoli selekční výhoda pro mutaci třetí. Z toho vyplývá, že muselo dojít ke třem nezávislým mutacím, než organizmus vůbec získal nějakou selekční výhodu. Zásadní otázkou tedy je, zda je pravděpodobné, aby u téhož jedince došlo neřízenou náhodou k několikanásobným mutačním změnám, známe-li mutační tempo i velikosti populací. Ani Hughes, přestože jinak apeluje na kolegy evoluční biology, aby byli ve svých výzkumech pečlivější, se touto kardinální otázkou nezabývá.
Podobnou záležitostí je kritika čelného paleoantropologa Bernarda Wooda: konstatuje v ní, že modely evoluce lidských lebek jsou příliš zjednodušující, protože postulují příliš mnoho mutací k získání nějaké funkční výhody:
- „Ty částečné mutace by přece dočasně snížily darwinovskou zdatnost dotčených jedinců…A zafixovaly by se teprve tehdy, až by došlo i k mutacím zmenšujícím zuby a čelisti a zvětšujícím mozek. Jak velké jsou pak šance na to, aby vše tak dokonale klapalo? (30)
V podobném duchu píše Jerry Coyne, že „však také musíme uznat, že přírodní výběr nemůže vybudovat žádný znak, aniž by dílčí kroky, jimiž postupuje, nepřinášely organizmu čistý zisk“ (31). Tenhle postřeh vypichuje zásadní slabinu mnoha neodarwinovských interpretací genové evoluce. Nedokládají totiž dostatečně přesvědčivě, zda jsou procesy potřebné k vygenerování nové funkční a výhodné genetické informace vůbec možné. Jak ukazují shora citované Hughesovy či Woodovy příklady, k získání jakékoli selekční výhody jsou zřejmě třeba mutace vícenásobné. Kterékoli vysvětlení počítající se slepými, neřízenými, náhodnými mutacemi způsobujícími vývoj genu od funkce A k funkci B se pak musí vypořádat nejméně s těmito třemi otázkami:
- Otázka: Existuje smysluplná řada dílčích kroků vedoucí ke zmutování genu A v gen B se selekčními výhodami získanými na každém takovém kroku?
- Otázka: Není-li tomu tak, jsou vůbec k získání či zlepšení funkce vícenásobné specifické mutace nutné?
- Otázka: A jsou-li už nutné, do jaké míry je pravděpodobné, že nastanou – při zakalkulování jejich stochastických zdrojů?
Matematik David Berlinski přemýšlí o takovýchto problémech ve své kritice evolucionistických výkladů vývoje oka. Darwinovské procesy zde selhávají, protože k získání nové funkce musí proběhnout celá řada změn:
- „Dochází-li k těmhle změnám najednou, pak nemá smysl bavit se o postupném zdolávání Hory nepravděpodobnosti. Nedochází-li k nim najednou, není jasné, proč by k nim mělo vůbec docházet (32).
Klíčový problém zde tedy proto opět spočívá v tom, jak těžce či lehce se rodí nová funkční biologická informace. Abychom na tuhle otázku dokázali odpovědět, musíme zjistit, do jaké míry jsou náhodné mutace a přírodní výběr s to takovou informaci vytvořit. Při své hře na evoluci genů se však většina evolučních biologů zmíněným hodnocením vyhýbá a jen zřídkakdy se ve svém bádání zabývá těmito otázkami. Místo toho většinou přivolají na pomoc procesy jako je genová duplikace, přírodní výběr a genová přeskupení aniž by doložili, zda na vytvoření potřebné informace náhodné a neřízené mutace vůbec stačí. A ani jakékoli jiné vysvětlení, byť stavící na poněkud složitějších procesech než je „duplikace, přeskupení či přírodní výběr“, ještě nedokazuje, že nové funkční geny mohou vznikat neřízeně.
A. Položme otázku 1 a 2:
Molekulární biolog Doug Axe podrobil některé enzymy testům citlivosti na mutace a zjistil, že pravděpodobnost vzniku funkčních proteinových terciálních struktur je 1 ku 1077 (33). Z jeho výzkumů dále vyplývá, že takhle nějak vypadá oblast zdatnosti mnoha enzymů, což znamená, že je velmi nepravděpodobné, aby neodarwinovské procesy vygenerovaly právě ony požadované sekvence aminokyselin, které vytvoří funkční proteinové terciální struktury.
Abychom dali názorný příklad: tyto výsledky svědčí o tom, že šance, že darwinovské procesy vygenerují funkční terciální proteinovou strukturu, je menší než šance někoho, kdo se zavřenýma očima vystřelí šíp do Mléčné dráhy a zasáhne přitom konkrétní předem určený atom (34). Tohle konstatování, mírně řečeno, vyčerpává naše stávající zdroje poznání pracující s počtem pravděpodobnosti. Takováhle data nám pak pomáhají zodpovědět první otázku: nepřichází vůbec v úvahu, aby se cestou dílčích mutací stala z funkce A funkce B.
Douglas Axe není zdaleka jediným biologem, který dospěl ke zmíněnému závěru. Uznávaná vysokoškolská učebnice biologie, Campbell´s Biology, konstatuje, že „i nepatrná změna primární struktury může ovlivnit konformaci proteinu i jeho funkčnost“ (35). V podobném duchu píše evoluční biolog David S. Goodsell:
- „Jak si asi dovedete představit, jen zlomeček možných kombinací aminokyselin se spontánně poskládá a vytvoří tak stabilní strukturu. Vytvoříte-li protein s náhodnou sekvencí aminokyselin a vložíte ho do vody, vznikne tak akorát mazlavý sterilní slepenec. Buňky si zdokonalovaly své aminokyselinové sekvence po mnoho let evolučního výběru…“ (36)
(konformace = uspořádání molekul dané konstituce odpovídající více nebo méně volné rotaci kolem vazeb (typicky kolem jednoduché vazby); konfigurace na stereogenních centrech molekuly se přitom nemění. Při změnách konformace překonává molekula energetické bariéry (každá stabilní konformace odpovídá určitému energetickému minimu); mění se „tvar“ molekuly, bez porušení vazeb. Pozn. překl.)
Goodsell se ovšem nezmiňuje o tom, že jsou-li „zdokonalené“ aminokyselinové sekvence a funkční proteinové terciální struktury vzácné a může-li přitom i nepatrná změna vést k narušení správného fungování, pak je krajně nepravděpodobné, že by přírodní výběr umožnil zmíněným proteinům přejít z jednoho funkčního terciálního uspořádání do druhého, aniž by mezitím prošly jistým stadiem, kdy by prostě fungovat na chvíli přestaly. Takže jak vlastně dochází ke vzniku nových fungujících proteinových terciálních struktur? Zde tedy naše úvaha fakticky odpovídá na druhou shora položenou otázku: aby geny vyvíjející nějakou novou funkci mohly přežít stadia, kdy na chvíli přestanou fungovat, musí projít mnoha specifickými mutacemi. Následující otázka 3 zjišťuje, zda je pravděpodobné, že se tak stane.
B. Položme otázku 3:
Roku 2004 zveřejnili Michael Behe a fyzik David Snoke v časopisu Protein Science článek referující o výsledcích počítačových simulací a teoretických propočtů. Vyplynulo z nich, že v populacích vícebuněčných organizmů je pouhý vznik základní fungující vazby mezi dvěma proteiny darwinovskou evolucí vysoce nepravděpodobný. Důvodem je, zjednodušeně řečeno, že neadaptivní mutace by musely zafixovat příliš mnoho aminokyselin dřív, než by mohla začít nějaká fungující vazba mezi nimi. Tito vědci zjistili, že:
- Se ukazuje skutečnost, že teprve při velmi značné velikosti populace – 109 či více – může v organizmu dojít k vybudování toho nejmenšího (multireziduálního) tělesného znaku vyžadujícího v průběhu oněch 108 generací změny dvou nukleotidů procesy popsanými v našem modelu, a že ke vzniku mnohem složitějších znaků nebo ke změnám proběhnuvším rychleji je třeba už nesmírně velký počet populací. Z toho vyplývá, že pouhý mechanizmus genových duplikací a bodových mutací by zde nestačil, přinejmenším pokud jde o mnohobuněčné diploidní druhy, protože jen málo mnohobuněčných druhů dosahuje zmíněné četnosti populací. (37)
Uvedená data tedy svědčí o nepravděpodobnosti vzniku byť pouhých dvou nutných neadaptivních mutací u mnohobuněčných diploidních druhů za nějakou přijatelnou dobu jen tak náhodou. A to je naše odpověď na třetí shora položenou otázku: pro jeden určitý mnohobuněčný organizmus je extrémně obtížné získat vícečetné specifické neadaptivní mutace, a více než dvě potřebné neadaptivní mutace už jsou nad veškeré možnosti mnohobuněčného organizmu. Studie jako je tahle tedy prokazují, že náhodné mutace a neřízený výběr prostě dost dobře nejsou s to vytvořit byť jednoduché nové genetické funkce.
Roku 2008 se kritici Beheho a Snoka pokoušeli v časopisu Genetics odmítnout výsledky jejich výzkumu, ale museli konstatovat, že získání pouhých dvou specifických mutací procesem darwinovské evoluce „u lidí o mnohem méně efektivním rozsahu populace, by tento typ změny vyžadoval > 100 milionů let“. Zmínění kritici připustili, že „je velmi nepravděpodobné, že by k tomu za nějakou rozumnou dobu došlo“ (38). Jinými slovy, člověk má příliš mnoho složitých a specifických informací v mnoha proteinech a enzymech, aby se daly vygenerovat darwinovskými procesy během nějaké přijatelné evoluční doby.
Jak již bylo konstatováno ve výkladu hry na evoluci genů, když se neodarwinisté pokoušejí vysvětlit evoluci genů, nevystačí jen s bodovými mutacemi k vysvětlení genové sekvence. Musí se proto uchylovat ke genetickým přeskupováním jako jsou inzerce, delece nebo údajný proces zvaný „míchání domén“, kdy jsou části bílkovin přesunuty na nová místa v genomu. Ve své knize Nepřekonatelná hranice evoluce referuje Michael Behe o výzkumech, v nichž vědci záměnou domén získali nové funkce bílkovin, přičemž zjistili, že tyhle inteligentně navozené změny vyžadují vícenásobné modifikace, které by v přírodě vyžadovaly mnoho simultánních mutačních událostí k vytvoření funkčních změn:
- Výzkum umělé syntézy nových proteinů] nenapodobuje náhodné mutace. Je pravým opakem náhodných mutací. …A co nám vlastně výsledky z laboratoře vypovídají o náhodném, avšak účinném míchání domén, „ke kterému dochází s význačnou frekvencí za podmínek možných i v přírodě“? Zcela vůbec nic. Sestaví-li vědec záměrně fragmenty genů tak, aby maximalizoval šance k jejich funkčnímu propojení, odhodil tím Darwina hodně, hodně daleko… [V pokusech uměle syntetizujících proteiny promícháváním domén] nespojí vědci pouze příslušné dva geny v jediném kroku; musí se vždy uskutečnit ještě několik kroků dalších…Pamatujme: čím větší množství kroků musí nastat k užitečným stavům, tím méně přijatelné je darwinistické vysvětlování…Promíchávání domén by bylo příkladem „přírodního genetického inženýrství“, jak je zastává James Shapiro, který doufá, že evoluce cestou velkých náhodných změn dokáže to, co nezvládne evoluce cestou malých náhodných změn. Náhoda však zůstává náhodou. Ať už opice přeskupuje jednotlivá písmena či celé kapitoly, stejně její snažení probíhá chaoticky a končí krachem. …Jeden krok v takovém procesu snad šťastnou náhodou „zafunguje“, možná na něj konstruktivně naváže i krok druhý. Neinteligentní procesy jako takové, a zejména procesy darwinovské, však prostě logicky souvislé systémy nepostaví. Z biologického hlediska je tedy mnohem rozumnější závěr, že podobně jako zbrusu nová vazebná místa mezi proteiny, tak i uspořádání genetických prvků do stavu logických sofistikovaných spojení – podobně jako je tomu u počítačů – je hodně daleko za možnostmi darwinovské evoluce. (39).
Jak podotýká Behe, „Ať už opice přeskupí ojedinělá písmena či celé kapitoly, každý její krok bude zamořen též zmatečností.“ Takže je-li k získání nějaké funkční výhody třeba více mutací – ať už mutací bodových, „míchání domén“ nebo jiných druhů přeskupení – , zdá se nepravděpodobné, aby onu novou biologickou funkci vytvořily slepé neodarwinovské procesy.
Bohužel, jen málo zastánců zmíněných neodarwinovských pohádek (pokud vůbec nějací) zkoumá, zda mutace a přírodní výběr zvládnou vytvořit novou funkční genetickou informaci. Místo toho prostě věří, že podobnosti i rozdíly mezi geny svědčí o tom, že k nedarwinovské evoluci opravdu došlo a mají za to, že „pozitivní výběr“ je dostatečným vysvětlením.
Jak varuje Hughes, evolucionisté „používají k ověřování zmíněné hypotézy jisté pochybné statistické metody“, v důsledku čehož „zaplavují evolučně-biologickou literaturu extravagantními tvrzeními o pozitivním výběru“, což vede k „masivní pseudodarwinovské bombastické reklamě, a tím je poškozováno dobré jméno evoluční biologie jako vědy.“ (40). Michael Behe varuje, že evolucionisté zaměňují pouhou podobnost sekvencí s důkazy pro neodarwinovskou evoluci. A Michael Lynch varuje své kolegy, že „Evoluční biologie není cvičením ve vymýšlení příběhů a cílem populační genetiky není něco lidem vnuknout, nýbrž vysvětlit“ (41).
Na podkladu těchto zásad probereme teď kriticky zhruba tucet takových pohádek o původu genů, které nabízejí práce citované NCSE.
VII. Prověření blafů o evoluci nové genetické informace
V průběhu procesu Kitzmiller v. Dover se soudce Jones řídil názory Kena Millera a NCSE čerpajícími z recenze v Nature Reviews Genetics, jejímž autorem byl mimo jiné Manyuan Long (42). Jones přitom tvrdil, že zmíněná recenze vychází z „vědeckých prací, které prošly procesem peer-review, a které prokazují původ nové genetické informace evolučními procesy“ (43). Ve skutečnosti Long et al. vlastně demonstrují, že neodarwinisté nechtějí klást správné otázky – obtížné otázky – týkající se kompetence jejich teorie vysvětlit evoluci genů. Přijímají jen povrchní pohádky namísto podrobných, hodnověrně doložených vysvětlení.
Stejně jako ve „hře na evoluci genů“ pracují i studie citované v recenzi Longa et al. znovu a znovu s pojmy jako je genová duplikace, přírodní výběr a genové přeskupení. Většina z nich pak nenabízí prakticky nic než vágní povídačky, které se dopouštějí týchž chyb, před kterými varuje Lynch – zaměňují vyprávění příběhů za vysvětlení.
Abychom ukázali, jak moc čerpá NCSE z Longa et al. ve své odpovědi na knihu Zkoumání evoluce, ukažme si, v jaké podobě reprodukuje NCSE jejich obsáhlejší tabulku (Tabulka 2) od Longa et al. Tabulka je vlastně seznamem řady genů, jejichž evoluční původ prý umíme vysvětlit (44). Mnoho příkladů ze zmíněné tabulky je pouhé cvičení ve vyprávění příběhů založené na domněnkách, a nic nevysvětluje ani nezodpovídá hlubší otázky po tom, jak neodarwinovská evoluce generuje novou funkční genetickou informaci:
a. Jingwei
První heslo v uvedené tabulce pochází ze studie Longa a Charlese Langleya v Science. Tvrdí se tam, že gen octomilky jingwei vznikl zpětným přenosem části jiného genu, Adh, do nového lokusu na jejím chromozomu blízko kopie genu yellow-emperor (45). Důkazem obou vědců pro tvrzení, že k takovémuto přeskupení došlo, je podoba sekvencí části jingwei a Adh i části jingwei a yellow-emperor. Takže s odvolávkou na pravidla 1 a 3 hry na evoluci genů se nám autoři snaží namluvit, že hypotetické duplikáty yellow-emperor a Adh byly šťastnou náhodou spojeny tak, že vytvořily nový funkční gen – jingwei. Přesná formulace, kterou autoři používají, zní, že exony byly kdesi „naverbovány“ a dosazeny do genomu „zachycením několika výše položených exonů a intronů nepříbuzného genu“ a vytvořily přitom „nový funkční gen“. Autoři se přitom ani nepokoušejí řešit důležitější otázky, jako třeba, zda k této cestě dílčích kroků ke genomickému přeskupení mohlo dojít jen tak neřízenou šťastnou náhodou, a tak vytvořit tento gen. Pouhý fakt nalezení sekvenční podobnosti mezi exony a jinými geny (či pseudogeny) proto nedokazuje, že probíhá neodarwinovská evoluce.
Long et al. tvrdí, že jingwei je starý pouze 2.5 milionu let, původní studie však srovnávala exon podobný Adh v jingwei s údajným výchozím exonem z Adh a zjistila, že jsou tak odlišné, že se jejich evoluční vývoj musí ubírat vlastními cestami již alespoň 30 milionů let. A v tom je problém, protože kladogeneze zmíněné octomilky nezačala podle vědeckých zjištění ani zdaleka tak brzy; jak píší Long a Langley, „Shora uvedené stáří exonů je tak v rozporu se stářím podskupiny melanogaster odhadovaným na 17 až 20 milionů let“. Ještě zvláštnější je fakt, že evolucionisté považují nezvykle vysoký stupeň odlišnosti mezi exony za důkaz toho, že jingwei „reagoval na tlak pozitivního přírodního výběru a vyvinula se u něho nová funkce“. Podle jednoho komentátora však navzdory faktu, že vědci postulují takovýto vývoj, „zůstává skutečná funkce jingwei zatím zahalena tajemstvím“ (46). Takže vědci sice tvrdí, že hnacím mechanizmem zkoumané změny byl přírodní výběr, přitom si však vůbec nejsou jisti tím, zda zkoumaný gen má nebo nemá vůbec nějakou funkci. Nezabývají se totiž hlubšími otázkami evoluce genů a místo toho nabízejí fragmentární vysvětlení založené na dohadech, které nerespektuje varování Austina Hughese před bezhlavým prosazováním „pozitivního výběru nezohledňujícího standardní biologické mechanizmy“ (47).
b. Sdic
Druhá studie citovaná tabulkou 2 tvrdí, že proběhla duplikace řady genů a jejich části se pak sloučily a vytvořily gen „de novo“ – nový gen. (48). Autoři chtěli objasnit, jak se část jednoho genu, Cdic, spojila s částí genu jiného, Annx, zabředli však do obtíží, protože ony geny jsou na chromozomu uspořádány jinak než gen studovaný. Za použití krkolomného výkladu pravidel 1 a 3 hry na evoluci genů spekulují zmínění autoři o tom, že k tomu, aby tento gen vznikl, proběhla série duplikací a přeskupení – vysoce selektivní a specifické delece – a pak ještě další duplikace. Zahrnovalo to i spontánní přeměnu jedné nekódovací oblasti v oblast kódovací, což je nazváno vznikem genu de novo. Poté, co vylíčili tento složitý příběh, uzavřeli autoři svůj článek konstatováním, že Sdic vznikl „rozsáhlou přestavbou“ genomu.
Za prvé, i když je charakteristickou funkcí Sdic být promotorem specifickým pro varlata, přece jen se tahle neobvyklá regulační oblast v pravém slova smyslu „nevyvinula“. Byla prapůvodní, vytvořená de novo šťastným setkáním vhodných sekvencí ležících vedle sebe. K rozsáhlejším evolučním změnám došlo spíše na intronu 3 Cdic; ty umožnily původně nepřeložitelné sekvenci stát se novou kódovací oblastí, jejíž produkt funguje ve struktuře axonemálního dyneinu (49).
Takový vznik fungujícího genu „de novo“ je událostí, kterou i Long et al. označují za „neobvyklou“ (50). Autoři se pak dovolávají účinného pozitivního výběru při tomhle procesu, protože jinak je nepravděpodobné, že by taková dramatická reorganizace „byla odstartována a probíhala bez pozitivního výběru.“ Ale i když postulují pozitivní výběr, připouštějí autoři, že ani pořádně nevědí, jakou funkci gen má, když konstatují: „Ještě nevíme, jak přispívá Sdic k fungování spermatické axolemy, ani zda hraje nějakou zásadní roli v mužské plodnosti.“ Takže jsme opět u toho, jsou si jisti, že se vyvinul díky „pozitivnímu výběru“, ale ani pořádně nevědí, pro jakou funkci ho příroda vybrala.
Vytvoření genu „de novo díky tomu, že se zrovna nacházely vedle sebe vhodné sekvence“, tedy pomocí mechanizmu, který je „vzácný“, nesvědčí nutně o tom, že gen vznikl evolucí. Tahle torzovitá pohádka se pouze vágně odvolává na řadu mutací, aniž by však zkoumala, zda jsou vůbec pravděpodobné či jakou výhodu nabízejí. Takže tahle bajka vlastně nic nevysvětluje.
c. Cid
Autoři tohoto článku studovali rozdíly v nukleotidech mezi geny Cid u dvou blízce příbuzných druhů octomilek a zjistili, že rozdíly v nukleotidech projevující se změnami aminokyselinové sekvence byly skoro 10krát běžnější než rozdíly „tiché“, které aminokyselinovou sekvenci neovlivňují (51). Když na tento jev zmínění vědci aplikovali předpoklady darwinizmu a pravidlo 2 hry na evoluci genů, dospěli k závěru, že se gen vyvinul díky tlaku pozitivního výběru.
V téhle studii však svedli na přírodní výběr nejen to, proč se geny změnily, nýbrž i to, proč zůstaly stejné: nízký počet změn nahrazením je zde totiž vydáván za důkaz „direktivní selekce“ (selective sweep), účinného čisticího výběru, který vyřadil odchylky, aby zabránil změnám v jedné linii. Takže za důkaz přírodního výběru je zde považován jak vysoký stupeň výskytu rozdílů měnících aminokyseliny, tak jejich nízký výskyt. Zda je jedno z obou pojetí správné, to je pak čistě otázkou ad hoc učiněných hypotetických závěrů i hypotetických východisek. Navíc neposkytli autoři svou interpretaci toho, jaké mají jednotlivé konkrétní mutace selektivní výhody (nebo zda v tom kterém případě výhoda není prokazatelná) vygenerované eventuálně tou kterou změnou aminokyseliny.
Ve světle takové podivné metodologie přichází člověku na mysl varování Michaela Lynche. Je „mýtem“ myslet si, že „popis vnitřně specifických rozdílů na molekulární a/nebo buněčné úrovni se zároveň rovná rozpoznání mechanizmů evoluce.“ Kromě toho porušuje tahle studie výstrahu Austina Hughese před „širokým využíváním jistých nepromyšlených statistických metod testování pozitivního výběru“, což vede k tomu, že „je evolučně biologická literatura zaplavována extravagantními tvrzeními o pozitivním výběru opřenými pouze o počítačové analýzy“ a k „přehršli pseudodarwinovských fíglů bytostně poškozujících důvěryhodnost evoluční biologie jako vědy“ (52). Je třeba také poznamenat, že tato studie zkoumala pouze to, jak vznikly variace téhož genu u dvou blízce příbuzných druhů, a nikoli v první řadě to, jak vzniká gen nový.
d. Arktické AFGP a antarktické AFGP
Dva články citované tabulkou 2 v Long et al. rozebírají otázky původu genů bránících zmrznutí (AFGP) u dvou druhů arktických a antarktických ryb. Zmíněné geny jsou u obou druhů podobné, i když jejich nositelé žijí doslova na opačných pólech zeměkoule a jsou příbuzné jen vzdáleně. Neodarwinisté tento jev vysvětlují prostě tím, že se „téměř totožné glykoproteiny bránící zmrznutí“ (53) vyvinuly nezávisle na sobě u vzdáleně příbuzných druhů ryb – jednoho v Arktidě a druhého v Antarktidě – procesem zvaným „neobvyklá konvergentní evoluce“ (54).
S použitím pravidel 1 a 3 hry na evoluci genů konstatuje studie hodnotící tento výzkum, že geny vznikly „duplikací, divergencí a smícháním exonů“ a byly „slepeny k sobě z kousků DNA s odlišnými funkcemi (nebo bez funkce vůbec)“ (55). Komentátoři dále uvádějí, že pokud jde o klíčové součásti zkoumaného genu u arktické tresky, badatelé „nenašli v databázích žádné podobné úseky ke zkoumané sekvenci“ (56) a proto nemohli určit její původ. Pro sekvenci antarktického AFGP však podobnosti existují – jde o podobnosti s částí genu pro trypsinogen. To vedlo ke spekulaci o evolučním schématu, který začíná genem pro trypsinogen, který byl potom skoro celý smazán, načež byl „získán“ krátký kódovací prvek threonin-alanin-alanin, a všechno to vyústilo do „zvětšení krátké sekvence DNA de novo, která pak dala vznik novému proteinu s novou funkcí“ (57). Z tohoto „de novo rozšíření kódovacího prvku vznikla zcela nová kódovací oblast fixující repetitivní tripeptidovou páteř AFGP“, přestože tato klíčová složka „vznikla (zčásti) z nekódovací DNA“ (58). Takže podle jejich výkladu začala nekódující DNA spontánně fungovat, došlo k jejímu zmnožení, a vytvořila základní funkční „páteř“ tohohle genu. Badatelé se přitom ani nepokusili zjistit pravděpodobnost mutací takové DNA, která „nemá vůbec žádnou funkci“ a náhle z ní je klíčová funkční složka tohoto genu.
Zmíněná evoluční povídačka řeší problémy rovněž vágními odvolávkami na pravidlo 2 hry na evoluci genů. Snaží se totiž vysvětlit onu spoustu genových změn nutných k náhlému vytvoření fungujícího genu zabraňujícímu zmrznutí prostým poukázáním na „silný selekční tlak prostředí“: ryby prostě potřebovaly přežít v chladné vodě (59). Přitom samozřejmě nebyly provedeny žádné statistické analýzy ke zjištění míry pravděpodobnosti toho, že se podaří zflikovat dohromady funkční geny ze zcela nepříbuzných úseků DNA (z nichž některé předtím vůbec nefungovaly) a vytvořit tak nový fungující gen pro substanci bránící zmrznutí. Jeden z článků místo toho prostě postuloval „tvůrčí“ potenciál „molekulárních mechanizmů“:
- „Považovat záležitost s AFGP za zvláštní případ duplikace a divergence by bylo přílišným zjednodušováním celé věci; je totiž jasné, že zprostředkování obrany proti zmrznutí nebo třeba i příbuzná funkce, která po přestavbě mohla tuhle obranu zajistit, nebyly trypsinogenu vlastní. Molekulární mechanizmy účastnící se tvorby zmíněného genu pro substanci bránící zmrznutí byly vskutku tvořivější – vytvořily smysluplné z toho, co smysl nemělo – , když vyvolaly fungující kódovací schopnost z intronové sekvence DNA (60).
Je vůbec pravděpodobné, aby zmíněné molekulární mechanizmy vyprodukovaly diskutovaný gen? Je pravděpodobné, aby náhodné mutace „vytvořily smysluplné z toho, co smysl nemělo“? Nebyl k tomu dán žádný rozbor. Geny pro substance bránící zmrznutí tvoří polyproteiny, tedy složité komplexy proteinů určené k rozřezání na mnoho různě dlouhých částí plnících pak různé funkce při obraně ryb před zmrznutím. Zmíněné segmenty vznikají pomocí zvláštních separátorových markerů a štěpí je specifické proteázy. Zde je třeba poznamenat, že nikdo zatím neanalyzoval ani původ těchto přidružených proteázových enzymů pro štěpení, nutných pro fungování genu AFGP .
Zmíněné články zakládají svá tvrzení o evoluci výhradně na nahodilých důkazech – srovnáváním podobností sekvencí – a pak je doplňují povídačkami o delecích, promíchávání a zvětšování. Výklad původu zkoumaných genů, které byly „zbastleny“ cestou „duplikací, divergencí a promícháváním exonů“ a „de novo“ získáním nekódujících sekvencí nevysvětluje, jak vlastně tak složitý gen mohl vzniknout. Tyto evoluční příběhy nechávají rovněž stranou otázku, jak se vlastně tento proteinový komplex („mnoho proteinů v jednotné podstatě“) mohl vyvinout. Stejně tak se evolucionisté nezamýšlejí nad pravděpodobností spontánního vzniku takového funkčního genu. Ani se tito vědci nepokusili vysvětlit krajně nepravděpodobný jev, kdy se u dvou druhů ryb vyvinuly nezávisle téměř identické proteiny chránící je před zmrznutím.
Uvedené proteiny jsou přitom vysoce repetitivní a jejich stavba je zřejmě méně specificky složitá než stavba většiny ostatních proteinů. Nicméně jejich studium nevykazuje žádné skutečné známky neodarwinovské evoluce, zaměřuje se pouze na srovnávání sekvencí a vynechává spoustu podrobností.
e. Adh-Finnegan
Tento Longem et al. citovaný článek shrnuje výsledky výzkumu úseku DNA považovaného nejprve za „nefunkční“ pseudogen, ze kterého se posléze vyklubal gen fungující (61). Tenhle „vzkříšený“ gen pak vědci pojmenovali Adh-Finnegan po „Timu Finneganovi, postavě irské lidové písničky, který byl omylem prohlášen za mrtvého, pak se ale probral a vstal.“ Jde o dobrý příklad toho, jak mýtus o odpadní DNA (junk-DNA) způsobil, že si vědci nejprve udělali o uvedeném genu nesprávnou představu.
Povídačky obsažené ve zmíněném článku čerpají ze všech tří pravidel hry na evoluci genů. Přestože ji citují Long et al. (a posléze i NCSE), vrhá studie velmi málo světla na původ zkoumaného genu; omezuje se na konstatování, že se vyvinul z jiného vysoce podobného genu Adh, a pak na sebe „nabalil“ sekvence cestou přeskupení z dalších míst v genomu. Jak se dalo očekávat, původ genu vysvětlují vědci dávnou duplikační událostí, a pak se odvolávají na výběr coby kouzelný proutek, jehož mávnutím došlo k „radikální změně ve struktuře“ genu „ve srovnání se strukturou jeho dobře zachovaného předchůdce Adh.“
Na rozsáhlá přeskupování je opět poukázáno, když se má vysvětlit, jak gen „naverboval asi 60 nových aminokyselin s N-koncem“ a také tehdy, když se má vysvětlit, jak tento gen „opatřil nové aminokyselinové zbytky v protisměru k řetězcům původního iniciačního kodónu ATG“. Původ exonu s N-koncem je však problém, protože „v databázi nebyl nalezen žádný známý protein, který by se podobal exonu s N-koncem“ , a tak, jak Long et al. poznamenávají, gen musel „peptid získat z nějakého neznámého zdroje [sic].“ A dále tvrdí, že „rychlé tempo evoluce“ exonu znemožnilo jeho identifikaci. Takže na závěr článku vědci konstatují: „Zatím budeme předpokládat, že genomické přeskupení (snad plynoucí z nerovného crossing-overu) vložilo první exon z neznámého dárcovského genu do přilehlé 5´-oblasti původního Adh-ψ.“ Pravděpodobnost výskytu takových mutací, které by měly tyto úseky DNA náhle přeskupit na jedno místo, a tak vytvořit funkční gen, však autoři studie nikdy nezvažují.
(N-konec = označení pro aminový konec bílkoviny, tj. část bílkoviny, kde příslušný aminokyselinový zbytek je vázán svou karboxylovou skupinou a jeho aminoskupina –NH2 zůstává volná. Bílkoviny se v buňce na polyzomech syntetizují právě od N-konce. Pozn. překl.)
Nedbaje na výstrahu Austina Hughese tvrdí autor v rozporu se zdravým rozumem, že proběhla „rychlá adaptivní evoluce“ a že „pozitivní výběr hrál důležitou úlohu v evoluci“ tohoto genu, i když jeho funkci v organizmu neznáme.
f. FOXP2
Tento gen považují většinou vědci za faktor hrající roli při vzniku lidské řeči, i když není přesně známo, co a jak v organizmu působí (62). A jedna studie opravdu konstatuje, že „objev, že FOXP2 má zásadní význam pro řeč a jazyk, ještě sám o sobě neznamená, že se účastnil jejich samotného vývoje, protože jeho funkce mohla během evoluce člověka zůstávat nezměněna, zatímco další geny kódující řeč změnami procházely (63).
Studie citované Longem et al. srovnávaly lidský FOXP2 s kopiemi téhož genu u šimpanzů, goril, orangutanů, makaků i myší, a došly k závěru, že „FOXP2 je konzervovaným proteinem; jeho lidská podoba se liší od té myší v pouhých třech aminokyselinách (a jedné vložené a jedné deletované) z celkového počtu 715 aminokyselin.“ (64) Takže zmíněný článek vlastně nereprodukuje výsledky studia původu nového genu, nýbrž se pouze pokouší vysvětlit, jak vznikly pouhé dva rozdíly mezi aminokyselinovými sekvencemi genu FOXP2 lidí a lidoopů.
Vysoký poměr nesynonymických (tj. aminokyseliny měnících) k synonymickým (tj. tichým) nukleotidovým rozdílům byl zde brán za důkaz síly „pozitivního výběru“ (65). Opět se tedy předpokládá proběhnuvší proces výběru, přestože autoři přesně neznají funkci genu. To ignoruje výstrahu Austina Hughese před „ tvrzením, že došlo k pozitivnímu výběru, které je však založeno pouze na statistice, zatímco biologické mechanizmy jsou ignorovány“ (66). V zásadě zde studovali vědci pouze interspecifické rozdíly mezi lidským FOXP2 a týmž genem u jiných živočišných druhů a zjistili, že jsou pranepatrné. I kdyby zde tedy působily neodarwinovské mechanizmy, rozsah evoluce u lidského FOXP2 představuje 2 mutace a 2 změny aminokyselin. To je sice zajímavé zjištění, ale zcela neužitečné pro vysvětlení nějakých skutečně pozoruhodných či efektních stupňů evoluce genů.
g. Cytochrom c1
Tenhle článek se pokoušel vysvětlit původ genu cytochromu c1 účastnícího se produkce energie v rostlinách (67). Jeho autoři našli u tří exonů cytochromu c1 (genu operujícího v mitochondriích) sekvence podobné sekvencím genu s velmi odlišnou funkcí, GapC, který působí v cytoplazmě (68). A tahle podobnost byla hlavním argumentem, o který zmínění vědci opírají svůj evoluční příběh o přeskupení exonů – a museli hodně silně použít pravidlo 3 hry na evoluci genů. Jelikož je cytochrom c1 méně rozšířený než Gapc1, usoudili vědci, že Gapc1 je starší a je proto „dárcem“ exonů do cytochromu c1 formou „exonového promíchání“. Dále spekulují o tom, že původní gen cytochrom c1 měl tu samou funkci, avšak teprve zmíněné nové exony umožnily (z nějakého důvodu), aby se tato nová funkce projevila – ale mnohem efektivněji: „Původní gen cytochrom c1 v rostlinách musel být zaměřen na mitochondrii; v linii vedoucí k bramborám byla pak takhle cílová (target) sekvence nahrazena genem GapC. Tato výměna byla selektována zřejmě proto, že promotor genu Gapc přinášel rostlinám nějakou výhodu.“ A jak lze opět předpokládat, autoři téhle studie ignorují míru pravděpodobnosti mutací, které by vedly k nahrazení exonů jednoho genu exony „dodanými“ genem jiným, přičemž přestavovaný gen nejenže zůstane funkční, nýbrž k jeho původní funkci přibude ještě další výhoda. A přitom ona nová genetická informace vzniká právě v popsané klíčové fázi celého procesu; autoři studie však nikdy nezjišťují, zda je vůbec pravděpodobné, aby proběhla cestou neřízených mutací.
h. Morpheus
Tahle studie se zaměřila na vysvětlení původu skupiny genů zvané morfeus, která se změnila natolik, že ji nebylo možno spojit s žádným genem-předkem. Řečeno slovy zoufalých badatelů, „některé geny se objeví a vyvinou velmi rychle, a vygenerují kopie, které jsou velmi málo podobné svým dávným předchůdcům“, takže „v genomech modelových organizmů asi nenajdeme jejich zřetelné ortology“ (69). /tj. homologní pozměněné kopie – pozn. edit./ Zmínění vědci píší o tom, že se „nepodařilo zjistit žádnou významnou podobnost sekvencí téhle genové rodiny se sekvencemi jiných organizmů ani na úrovni nukleotidů ani proteinů“. Jelikož tedy nemohli sáhnout po prostředku duplikace či jiných přeskupeních, aby vysvětlili vznik tohoto genetického materiálu, spokojili se autoři studie konstatováním, že „Tato data svědčí o tom, že buď byly během evoluce téhle genové rodiny exonické oblasti hypermutabilní nebo došlo během evoluce k selekci změn těchto aminokyselin“ a že jejich vědecká „analýza odhalila neobvyklou evoluční pružnost“. Jinými slovy, prostě netuší, kde se tu tenhle gen vzal, a tak se utíkají k tvrzením, že geny byly „hypermutabilní“ a že byly pod tak silným selekčním tlakem, že jejich původ nelze vypátrat. Otázku, jak geny vlastně vznikly, si přitom autoři nikdy ani pořádně nepoložili. Takže člověk nevěří svým očím, když čte povídačky o silném selekčním tlaku, zatímco na druhé straně „přesnou funkci téhle genové rodiny neznáme“. Pravidlo č. 2 hry na evoluci genů tak opět vyřešilo veškeré problémy, aniž se kdo pokusil vypátrat, do jaké míry je tento mechanizmus skutečně akceptovatelný.
i. Tre2
Tato studie navrhla „chimérické spojení dvou genů“, aby tak vysvětlila, jak se gen Tre2 vyvinul z kopií dvou jiných genů. (70) Vyprávění je prosté: Tre2 má 30 exonů: exony 1-14 vypadají podobně jako jiný gen, TBCID3, zatímco exony 15-30 jsou podobné genu USP32. A tak autoři popisují původ tohoto genu jako „náhlé vytvoření mozaikového genu se dvěma novými funkcemi.“ A autoři také tvrdí, že „že událost přírůstku domény a fúze genů nemusí být vzácná,“ nenabídli však žádné zvážení pravděpodobnosti mutací, které by přeskupily tyto dva geny do podoby genu, který nejen funguje, ale má ještě navíc užitečné funkce nové.
j. Dntf-2r
Tato studie ve spolupráci s Longem, tvrdí, že Dntf-2r, gen octomilky, vznikl jako duplikát, který byl zpětně vložen z genu Dntf-2. Za použití pravidla č. 2 hry na evoluci genů, autoři se snaží vysvětlit následnou evoluci Dntf-2r odhadnutím poměru nesynonymických k synonymickým rozdílům. Za použití jednoho testu zjistili, že „polymorfizmus je vyšší pro synonymická místa než ta, kde došlo k nahrazení…což ukazuje na proces pročišťující selekce,“ jenže zase jiný test „ukázal významný přírůstek aminokyselinových substitucí, což naznačuje, že zrychlená evoluce proteinových sekvencí je pravděpodobně důsledkem procesu darwinistické pozitivní selekce.“ Aby vysvětlili tyto zdánlivě protichůdné výsledky, rozhodli se vědci, že „jak pročišťující selekce, tak i adaptivní evoluce,“ byly ve hře. Nicméně se nepokusili nějak přesně vysvětlit, které vlastně ty funkce tyto síly usilovaly zachovat a které změnit, protože funkci Dntf-2r neznají. Než se do této studie pustili, neexistovala „žádná informace o funkci Dntf-2r“, a po dokončení studie to jediné, co mohli říct, bylo, že „tento gen může produkovat funkční protein.“ Opět, pozitivní selekce je tím kouzelníkem, i když hodně „vzdáleným od jakéhokoliv biologického mechanizmu.“ (71) Určitě bychom rádi znali mutační dráhu nebo selektivní výhodu u navržených specifických mutací na této dráze. Nic z toho zde však není diskutováno, což znamená, že vysvětlení, jak evoluce tvoří novou genetickou informaci, v této studii chybí.
Autoři se pokusili vysvětlit také původ promotoru pro Dntf-2r, ale pravdivě poznamenali, že „Kritickým krokem pro budoucnost nově přemístěné sekvence (retropozicí) je, zda získá nový promotor. Integruje-li se taková sekvence do genomické, a postrádá potenciál k expresi, je odsouzena vyvinout se v pseudogen.“ Takže jak získal Dntf-2r svůj promotor? Zmínění vědci zjistili, že promotor genu Dntf-2r pochází naštěstí z DNA nacházející se blízko jeho lokusu (místa jeho inzerce), ale konstatují, že „není jasné, zda tahle již dříve existující sekvence představuje funkční promotor pro nějaký neznámý gen v této oblasti či zda je pouhou náhodnou genomickou sekvencí, která se náhodně podobala sekvenci promotorové“ (72). Autoři se přitom nepokoušejí zjistit, která z obou alternativ je vlastně věrohodná: nepropočítávají ani míru pravděpodobnosti toho, že se „náhodná genomická sekvence“ stala náhle fungující sekvencí promotorovou, ani pravděpodobnost toho, kdy by náhoda vložila gen hned vedle fungujícího promotoru.
(Promotor /P/ je úsek DNA, který je potřebný k transkripci konkrétního genu. Promotor bývá zpravidla na začátku genu a váže se na něj RNA polymeráza – pozn. edit.)
k. Sanguinaria rps1
K napsání tohohle článku vedl nález „tří výrazných distribučních anomálií při zkoumání obsahu mitochondriálních genů u krytosemenných rostlin“ (73). Jinými slovy, vědci našli geny u druhů, u kterých je v souladu s konvenčním chápáním původu ze společného předka neočekávali, protože tytéž geny byly předtím zjištěny u údajně „vzdáleně příbuzných kvetoucích rostlin“. Ragan a Beiko uvádějí, že „topologickou diskordanci mezi genetickým rodokmenem a důvěryhodným rodokmenem referenčním chápeme jako příklad LGT [laterálního transferu genů] na první pohled.“ (74) Autoři předpokládají, že tenhle fylogenetický nesoulad má na svědomí LGT. Článek tak vlastně nevysvětluje skutečný původ zmíněných genů, nýbrž jen předpokládá a tvrdí, že ať už se vyvinuly kdekoli a jakkoli, byly geny transplantovány do uvedených kvetoucích rostlin cestou LGT (také známého jako horizontální transfer genů čili „HGT“).
Na závěr autoři konstatují, že tahle data „poprvé nezvratně dokládají, že běžné geny prodělávají během evoluce rostlin evolučně častý HGT a mohou horizontálně dodávat DNA jiným rostlinám“. Připouštějí však, že otázka „Jak se geny přesunou z jedné rostliny do jiné, sexuálně nepříbuzné“, zůstává nezodpovězena. Jediným důkazem HGT u rostlin je tak fakt nerovnoměrného rozložení zmíněných genů odporující standardnímu modelu fylogeneze, nikoli nějaký zásadní poznatek o vlastním mechanizmu HGT u kvetoucích rostlin. Ve skutečnosti autoři studie připouštějí, že „horizontální transfer v oblasti evoluce zvířat, rostlin či hub je neznámý, kromě zvláštních případů mobilních genetických prvků“. Tento článek neříká prakticky nic o skutečném zrození uvedených genů evolučními procesy, ať už tyhle geny vznikly kdekoli, a zaměřuje se místo toho na domněnky a argumenty ad hoc, aby zachránil teorii o původu ze společného předka před falzifikací následkem protichůdných fylogenetických dat svědčících proti ní.
Při studiu tohoto genu u různých druhů rostlin narazili autoři článku na další dva příklady HGT; jeden z nich se týkal rostliny Sanguinaria canadensis (krvavěnka kanadská), dvouděložné rostliny z čeledi mákovitých, jejíž gen rpsl 11 „se jeví jako chimérický: jeho polovina s 5‘ vznikla, jak se dá očekávat, vertikálně z běžné dvouděložné rostliny, ale jeho polovina s 3‘ vznikla bezesporu horizontálně z rostliny jednoděložné“. Jinými slovy, polovina genu připomíná rpsl 1 dvouděložných a jeho druhá polovina rpsl 1 jednoděložných; proto ho označujeme jako „chimérický“. Podle téhle hypotézy byl do genomu Sanguinarie dopraven (neznámým mechanizmem) jednoděložný rpsl 1, a pak se prostě jen tak, náhodou, spojil s dvouděložnou verzí téhož genu a vytvořil nový fungující gen. Autoři se přitom zdržují úvah o tom, zda je vůbec jen vzdáleně myslitelné, aby byl gen přenesen z jiného druhu (neznámým mechanizmem) jen proto, aby se v novém genomu spojil s vlastním homologem – prostě jen tak – , a pak vytvořil nový fungující gen.
l. PMCHL
Přestože NCSE licoměrně ujišťuje, že „Pro biology není problémem doložit, jak nová informace (ve smyslu užívaném informatiky) vzniká, ani jak se vyvinou nové geny, různé druhy buněk či tkání“, začíná tato studie z roku 2001 doznáním, že „ Vysvětlit to, jak vznikají geny s nově specifikovanými funkcemi, zůstává základní otázkou“ (75). Podobně jako již citované příklady Sdic a AFGP vysvětlují vědci i původ PMCHL1 a PMCHL2 pomocí teorie o vytvoření klíčových složek genu „de novo“; jeho exon pak prý „vznikl z jedinečné nekódující sekvence“. Autoři popisují, že tento proces vyžaduje „vznik 3´exonů z jedinečné nekódující genomické sekvence, která šťastnou náhodou vyvinula standardní strukturu intron-exon a polyadenylační signální sekvence.“ Klíčové součásti zmíněného genu se tedy prostě „vyvinuly šťastnou náhodou“. Je tohle nějaké vysvětlení? Článek na druhé straně nechce povzbuzovat vědce ke svévolným výkladům, a tak jeho autoři upozorňují na to, že „se zdá, že k takovémuto vznikání de novo generací stavebních kamenů – jednotlivých genů či jejich součástí kódujících proteinové domény – dochází jen vzácně“.
Snahy vysvětlit zbytek tohoto genu jsou velmi klopotné, avšak pravidla 1 a 3 hry na evoluci genů přece jen umožnila autorům přivolat si na pomoc řadu přeskupení včetně retrotranspozic, inzercí a duplikací. Mluví tak o tom, že tyhle geny byly náhle „kooptovány“ či „‘exaptovány‘ do funkční role“. Na jedné straně původ genů s novými funkcemi je skutečně „základní otázkou“, na druhé straně se článek opírá o jakési teze o „vývoji díky šťastné náhodě“, což je ale hodně málo k vysvětlení této otázky. To je pravda zejména s ohledem na to, že autoři prostě vůbec nepropočítali míru pravděpodobnosti mutací měnících nekódující DNA v DNA kódující ani mutací tvořících a přeskupujících rozmanité segmenty genomu tak, aby vznikl nový fungující gen.
VIII. Závěr: Blafování NCSE o původu informace moc neřeknou
Mohlo by být uvedeno více příkladů z tohoto dokumentu, ale pointa je již dostatečně jasná: analýzy Longa a jeho spolupracovníků svědčí o naprosto nedostatečném vysvětlování, které nabízejí neodarwinisté, ohledně původu nové genetické informace.
Ani v jednom případě totiž shora uvedené články citované Longem et al. vlastně nevysvětlují, jak vznikla nová funkční informace. Chybí v nich prostě jakákoli analýza procesů, jakými by přírodní výběr mohl napomoci změnám navozeným mutacemi, ke kterým prý docházelo na každém kroku evoluční dráhy; mutační dráha, krok po kroku, v detailech, nebyla nikdy popsána. Zmíněné studie nabídly přinejlepším jen vágní konstrukce ad hoc postulující duplikace, přeskupování a přírodní výběr – které se často odehrály náhle, výjimečně a přerušovaně – , aby tak byl vysvětlen vznik zkoumaného genu. V mnoha případech sáhli vědci po přírodním výběru, aby tak údajně vysvětlili změny genů, aniž vůbec znali jejich funkce a byli tak s to identifikovat výhody z těchto funkcí plynoucí. Nikdy také uvedené práce nepropočítaly, zda vůbec existují dostatečné pravděpodobnostní zdroje pro vytvoření postulovaných mutací v nějakém představitelném časovém horizontu. V některých případech pak vědci prostě ani neznali genetický materiál, z něhož „jejich“ geny vznikly, nebo se ve studiích sahá po spontánním vznikání genů „de novo“ z dřívější nekódující DNA. Připustili sice ochotně, že k náhlému vzniku genu „de novo“ dochází jen zřídka, ovšem nikdy se nepokusili zjistit, zda je na základě matematické pravděpodobnosti takový neřízený mechanizmus alespoň vzdáleně možný. Zmíněné studie tak vycházejí pouze ze hry na evoluci genů a nikdy nepokládají ty správné otázky, aby vysvětlily, jak tvoří neodarwinistické mechanizmy novou genetickou informaci.
Citované blafování NCSE (i soudcem Jonesem) nevysvětlily, jak neodarwinovské mechanizmy vytvoří novou fungující biologickou informaci. Místo toho jsou mechanizmy postulované ve zmíněných článcích přinejlepším vágní a pouze hypotetické:
- exony prý byly „získány“ či „dodány“ z jiných genů (a v některých případech dokonce z „neznámého zdroje“);
- vyskytují se vágní proklamace, že „genomy prošly rozsáhlými přestavbami“;
- mutace prý způsobovaly „šťastná blízká setkání vhodných sekvencí“ v oblastech s genovými promotory, které se proto „vlastně ani ‚nevyvinuly‘ “;
- badatelé postulovali „radikální změny struktury“ způsobené „rychlou, adaptivní evolucí“ a tvrdili, že „pozitivní výběr hraje v evoluci genu důležitou úlohu“, přestože ani neznali funkci tohoto genu;
- geny byly údajně „zflikovány z DNA, která měla úplně jinou funkci (nebo která neměla vůbec žádnou funkci)“;
- předpokládalo se, ale nebylo doloženo, „vytváření“ nových exonů „z jedinečné nekódující genomické sekvence, která se souhrou náhod vyvinula“;
- předkládalo se nám k věření, že oblasti promotorů vznikly z „náhodné genomické sekvence podobné náhodou sekvenci promotoru“ nebo že gen vznikl tak, že byl čistě náhodou vložen hned vedle fungujícího promotoru;
- vysvětlování se často spokojilo s konstatováním, že došlo k „chimérickému spojení dvou genů“ založenému výhradně na podobnosti sekvencí;
- tam, kde neexistuje vůbec žádný dokladový materiál, řeknou nám vědci, že „se geny objevují a vyvíjejí velmi rychle a generují kopie, které se pramálo podobají genům výchozím“ protože jsou prostě „hypermutabilní“;
- setkali jsme se dokonce se „zarážejícím případem konvergentní evoluce téměř shodných“ proteinů;
Pro zapamatování: vědci nikdy nepropočítali míru pravděpodobnosti výskytu postulovaných nepravděpodobných jevů. Zarážející dále je, že zmínění badatelé opakovaně vysvětlovali zkoumané jevy působením přírodního výběru, i když třeba neznali funkci studovaného genu. Proto pak samozřejmě nemohli identifikovat žádné eventuální výhody získané postulovanými mutacemi. V případě, že bylo zapotřebí mutací několik, neověřovali si badatelé, zda ten který gen mohl fungovat (jestli byl životaschopný) i v průběhu takové zásadní přestavby. Kritizované články se hemží vágními historkami, ale neposkytují přijatelné, hodnověrně doložené vysvětlení původu nové genetické informace.
Moderní evoluční biologie nechává vskutku otevřeno mnoho otázek týkajících se toho, jak neřízený výběr za pomoci náhodných mutací vytvoří novou fungující biologickou informaci. Ze soudního rozhodnutí v Kitzmillerově případu pro nás plyne toto poučení: vědci dělají, jako by všechny problémy byly již vyřešeny, a přitom na mnoho otázek odpovědi zatím nemáme, určitě ne v neodarwinistickém paradigmatu. A proto špatný přístup soudce Jonese a jeho společníků z NCSE povede nejen k matení studentů, ale je zde i nebezpečí, že zbrzdí vědecký pokrok tím, že některé nejdůležitější otázky v biologii budou považovány za zodpovězené, i když ve skutečnosti zodpovězené nejsou. Je to naneštěstí pouhý mýtus, který se stal pilířem vysvětlování a obhajoby evoluce u soudů, ve vědecké obci, při vzdělávání a v médiích.
Odkazy
[1.] Nicholas Matzke quoted in Michael Powell, “Controversial Editor Backed,” Washington Post (August 19, 2005). [2.] Kenneth R. Miller, Kitzmiller v. Dover Day 1 AM testimony, pg. 135 (September 26, 2005). [3.] Kitzmiller v. Dover, 400 F.Supp.2d 707, 744 (M.D.Pa. 2005). [4.] Manyuan Long, Esther Betrán, Kevin Thornton, and Wen Wang, “The Origin of New Genes: Glimpses from the Young and Old,” Nature Reviews Genetics, Vol. 4:865-875 (November, 2003). [5.] The word “information” appears once in the entire article—in the title of note 103. Id. at 875 n. 103. See Manyuan Long, Esther Betrán, Kevin Thornton, and Wen Wang, “The Origin of New Genes: Glimpses from the Young and Old,” Nature Reviews Genetics, Vol. 4:865-875 (November, 2003). [6.] Nicholas J. Matzke and Paul R. Gross, “Analyzing Critical Analysis: The Fallback Antievolutionist Strategy,” pg. 42 in Not in Our Classrooms: Why Intelligent Design is Wrong for Our Schools (edited by Eugenie C. Scott and Glenn Branch, Beacon Press, 2006). [7.] Id. [8.] Bernd-Olaf Kuppers, Information and the Origin of Life (Cambridge: MIT Press, 1990), pp. 170–172. [9.] This calculation uses a 26 letter English alphabet that is not case-sensitive and, as seen in the strings, does not use spaces. [10.] String B was generated using a random character generator from the website Random.org. [11.] Jack W. Szostak, “Molecular messages,” Nature, Vol. 423:689 (June 12, 2003). [12.] Kirk K. Durston, David K. Y. Chiu, David L. Abel, Jack T. Trevors, “Measuring the functional sequence complexity of proteins,” Theoretical Biology and Medical Modelling, Vol. 4:47 (2007) (internal citations removed). [13.] Robert M. Hazen, Patrick L. Griffin, James M. Carothers, and Jack W. Szostak, „Functional information and the emergence of biocomplexity,“ Proceedings of the National Academy of Sciences, USA, Vol. 104:8574–8581 (May 15, 2007). [14.] Stephen C. Meyer, “The origin of biological information and the higher taxonomic categories,” Proceedings of the Biological Society of Washington, Vol. 117(2):213-239 (2004). [15.] Leslie E. Orgel, The Origins of Life: Molecules and Natural Selection, pg. 189 (Chapman & Hall: London, 1973). [16.] Comment by Michael Egnor at http://scienceblogs.com/pharyngula/2007/02/dr_michael_egnor_challenges_e… (February 20, 2007) [17.] Again, as implied in the body, if one could predict the string would be duplicated, then the Shannon Information would also not increase after duplicating the string, in which case there is no increase in CSI nor Shannon Information. [18.] Michael Lynch, “The frailty of adaptive hypotheses for the origins of organismal complexity,” Proceedings of the National Academy of Sciences, Vol. 104:8597–8604 (May 15, 2007). [19.] Austin L. Hughes, „The origin of adaptive phenotypes,“ Proceedings of the National Academy of Sciences USA, Vol. 105(36):13193–13194 (Sept. 9, 2008) (internal citations removed). [20.] Michael J. Behe, Darwin’s Black Box: The Biochemical Challenge to Evolution, pgs. 175-176 (Free Press, 1996). [21.] Michael J. Behe, The Edge of Evolution: The Search for the Limits of Darwinism, pg. 95 (Free Press, 2007). [22.] See for example, “Limits on Evolution” at http://ncseweb.org/creationism/analysis/extrapolations[23.] For example, when the ratio of nonsynonymous (i.e. amino acid changing) to synonymous (i.e. non-amino acid changing) differences between Gene B and Gene A is high, we have can say that it must be natural selection at work because only strong selection pressure would preserve so many changes that change amino acid sequence. Incredibly, we can also say that when the same ratio is low (i.e. there are FEW amino acid replacements in a gene), that too shows that natural selection was at work, in this case in the form of stabilizing selection to conserve gene sequence. This approach was taken in Harmit S. Malik and Steven Henikoff, “Adaptive Evolution of Cid, a Centromere-Specific Histone in Drosophila,” Genetics, Vol. 157:1293–1298 (March 2001) and its discussion of the Cid gene in a subsequent post. [24.] See for example Ulfar Bergthorsson, Keith L. Adams, Brendan Thomason, and Jeffrey D. Palmer, „Widespread horizontal transfer of mitochondrial genes in flowering plants,“ Nature, Vol. 424:197-201 (July 10, 2003). See also Mark A. Ragan and Robert G. Beiko, „Lateral genetic transfer: open issues,“ Philosophical Transactions of the Royal Society B, Vol. 364:2241-2251 (2009) (“topological discordance between a gene tree and a trusted reference tree is taken as a prima facie instance of LGT”). [25.] For example, this explanation was invoked in Matthew E. Johnson, Luigi Viggiano, Jeffrey A. Bailey, Munah Abdul-Rauf, Graham Goodwin, Mariano Rocchi & Evan E. Eichler, “Positive selection of a gene family during the emergence of humans and African apes,” Nature, Vol. 413:514-519 (October 4, 2001). [26.] Austin L. Hughes, „Looking for Darwin in all the wrong places: the misguided quest for positive selection at the nucleotide sequence level,“ Heredity, Vol. 99:364–373 (2007). [27.] Id. [28.] Id. [29.] “The modern synthesis is good at modeling the survival of the fittest, but not the arrival of the fittest.” Scott Gilbert, quoted in John Whitfield, “Biological Theory: Postmodern evolution?,” Nature, Vol. 455:281-284 (2008). [30.] Bernard Wood, quoted in Joseph B. Verrengia, “Gene Mutation Said Linked to Evolution,” Associated Press, found in San Diego Union Tribune, March 24, 2004. [31.] Jerry Coyne, „The Great Mutator,“ The New Republic (June 14, 2007). Coyne asserts he knows of no example where this is the case. [32.] David Berlinski, “Keeping an Eye on Evolution: Richard Dawkins, a relentless Darwinian spear carrier, trips over Mount Improbable. Review of Climbing Mount Improbable by Richard Dawkins (W. H. Norton & Company, Inc. 1996),” in The Globe & Mail (November 2, 1996) at http://www.discovery.org/a/132 [33.] Douglas A. Axe, “Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds,” Journal of Molecular Biology, Vol. 341: 1295-1315 (2004); Douglas A. Axe, “Extreme Functional Sensitivity to Conservative Amino Acid Changes on Enzyme Exteriors,” Journal of Molecular Biology, Vol. 301: 585-595 (2000). [34.] See Stephen C. Meyer, Signature in the Cell: DNA and the Evidence for Intelligent Design, pg. 211 (Harper One, 2009). [35.] Neil A. Campbell and Jane B. Reece, Biology, pg. 84 (7th ed, 2005). [36.] David S. Goodsell, The Machinery of Life, pg. 17, 19 (2nd ed, Springer, 2009). [37.] Michael J. Behe & David W. Snoke, “Simulating Evolution by Gene Duplication of Protein Features That Require Multiple Amino Acid Residues,” Protein Science, Vol 13:2651-2664 (2004). [38.] Rick Durrett and Deena Schmidt, “Waiting for Two Mutations: With Applications to Regulatory Sequence Evolution and the Limits of Darwinian Evolution,” Genetics, Vol. 180: 1501–1509 (November 2008). [39.] Michael Behe, The Edge of Evolution: The Search for the Limits of Darwinism, Appendix D, pgs. 272-275 (Free Press, 2007) (emphasis added). [40.] Austin L. Hughes, „The origin of adaptive phenotypes,“ Proceedings of the National Academy of Sciences USA, Vol. 105(36):13193–13194 (Sept. 9, 2008) (internal citations removed). [41.] Michael Lynch, “The frailty of adaptive hypotheses for the origins of organismal complexity,” Proceedings of the National Academy of Sciences, Vol. 104:8597–8604 (May 15, 2007). [42.] Manyuan Long, Esther Betrán, Kevin Thornton, and Wen Wang, “The Origin of New Genes: Glimpses from the Young and Old,” Nature Reviews Genetics, Vol. 4:865-875 (November, 2003). [43.] Kitzmiller v. Dover, 400 F.Supp.2d 707, 744 (M.D.Pa. 2005). [44.] See Limits on Evolution at http://ncseweb.org/creationism/analysis/extrapolations [45.] Manyuan Long & Charles H. Langley, “Natural selection and the origin of jingwei, a chimeric processed functional gene in Drosophila,” Science, Vol. 260:91–95 (April 2, 1993). [46.] John M. Logsdon, Jr., & W. Ford Doolittle, “Origin of antifreeze protein genes: A cool tale in molecular evolution,” Proceedings of the National Academy of Sciences USA, Vol. 94:3485-3487 (April, 1997). [47.] Austin L. Hughes, „Looking for Darwin in all the wrong places: the misguided quest for positive selection at the nucleotide sequence level,“ Heredity, Vol. 99:364–373 (2007). [48.] Dmitry I. Nurminsky, Maria V. Nurminskaya, Daniel De Aguiar, and Daniel L. Hartl, “Selective sweep of a newly evolved sperm-specic gene in Drosophila,” Nature, Vol. 396:572-575 (December 10, 1998). [49.] Id. [50.] Manyuan Long, Esther Betrán, Kevin Thornton, and Wen Wang, “The Origin of New Genes: Glimpses from the Young and Old,” Nature Reviews Genetics, Vol. 4:865-875 (November, 2003). [51.] Harmit S. Malik and Steven Henikoff, “Adaptive Evolution of Cid, a Centromere-Specific Histone in Drosophila,” Genetics, Vol. 157:1293–1298 (March 2001). [52.] Austin L. Hughes, „The origin of adaptive phenotypes,“ Proceedings of the National Academy of Sciences USA, Vol. 105(36):13193–13194 (Sept. 9, 2008) (internal citations removed). [53.] Liangbiao Chen, Arthur L. DeVries, & Chi-Hing C. Cheng, “Convergent evolution of antifreeze glycoproteins in Antarctic notothenioid fish and Arctic cod,” Proceedings of the National Academy of Sciences USA, Vol. 94:3817–3822 (April, 1997). [54.] John M. Logsdon, Jr., & W. Ford Doolittle, “Origin of antifreeze protein genes: A cool tale in molecular evolution,” Proceedings of the National Academy of Sciences USA, Vol. 94:3485-3487 (April, 1997). [55.] Id. [56.] Id. [57.] Liangbiao Chen, Arthur L. DeVries, & Chi-Hing C. Cheng, “Evolution of antifreeze glycoprotein gene from a trypsinogen gene in Antarctic notothenioid fish,” Proceedings of the National Academy of Sciences USA, Vol. 94:3811–3816 (April, 1997). [58.] John M. Logsdon, Jr., & W. Ford Doolittle, “Origin of antifreeze protein genes: A cool tale in molecular evolution,” Proceedings of the National Academy of Sciences USA, Vol. 94:3485-3487 (April, 1997). [59.] Liangbiao Chen, Arthur L. DeVries, & Chi-Hing C. Cheng, “Evolution of antifreeze glycoprotein gene from a trypsinogen gene in Antarctic notothenioid fish,” Proceedings of the National Academy of Sciences USA, Vol. 94:3811–3816 (April, 1997). [60.] John M. Logsdon, Jr., & W. Ford Doolittle, “Origin of antifreeze protein genes: A cool tale in molecular evolution,” Proceedings of the National Academy of Sciences USA, Vol. 94:3485-3487 (April, 1997). [61.] David J. Begun, “Origin and Evolution of a New Gene Descended From alcohol dehydrogenase in Drosophila,” Genetics, Vol. 145:375-382 (February, 1997). [62.] Wolfgang Enard, Molly Przeworski, Simon E. Fisher, Cecilia S. L. Lai, Victor Wiebe, Takashi Kitano, Anthony P. Monaco & Svante Pääbo, “Molecular evolution of FOXP2, a gene involved in speech and language,” Nature, Vol. 418:869-872 (August 22, 2002) (stating “to establish whether FOXP2 is indeed involved in basic aspects of human culture, the normal functions of both the human and the chimpanzee FOXP2 proteins need to be clarified”). [63.] Jianzhi Zhang, David M. Webb and Ondrej Podlaha, “Accelerated Protein Evolution and Origins of Human-Specific Features: FOXP2 as an Example,” Genetics, Vol. 162:1825–1835 (December 2002). [64.] Id. [65.] Id. [66.] Austin L. Hughes, „Looking for Darwin in all the wrong places: the misguided quest for positive selection at the nucleotide sequence level,“ Heredity, Vol. 99:364–373 (2007). [67.] Manyuan Long, Sandro J. de Souza, Carl Rosenberg, and Walter Gilbert, “Exon shuffling and the origin of the mitochondrial targeting function in plant cytochrome cl precursor,” Proceedings of the National Academy of Sciences USA, Vol. 93:7727-7731 (July, 1996). [68.] Id. Specifically, the authors write: “In a computer survey of an exon database, we observed a high similarity (44% identity and 64% similarity over 41 amino acids) between the 5’ three consecutive exons of the pea Gapc1 and the potato cytochrome c1 precursor.” [69.] Matthew E. Johnson, Luigi Viggiano, Jeffrey A. Bailey, Munah Abdul-Rauf, Graham Goodwin, Mariano Rocchi & Evan E. Eichler, “Positive selection of a gene family during the emergence of humans and African apes,” Nature, Vol. 413:514-519 (October 4, 2001). [70.] Charles A. Paulding, Maryellen Ruvolo, and Daniel A. Haber, “The Tre2 (USP6) oncogene is a hominoid-specific gene,” Proceedings of the National Academy of Sciences USA, Vol. 100(5):2507–2511 (March 4, 2003). [71.] Austin L. Hughes, „Looking for Darwin in all the wrong places: the misguided quest for positive selection at the nucleotide sequence level,“ Heredity, Vol. 99:364–373 (2007). [72.] Esther Betran and Manyuan Long, „Dntf-2r, a Young Drosophila Retroposed Gene With Specific Male Expression Under Positive Darwinian Selection,“ Genetics, Vol. 164:977–988 ( July 2003). [73.] Ulfar Bergthorsson, Keith L. Adams, Brendan Thomason, and Jeffrey D. Palmer, „Widespread horizontal transfer of mitochondrial genes in flowering plants,“ Nature, Vol. 424:197-201 (July 10, 2003). [74.] Mark A. Ragan and Robert G. Beiko, „Lateral genetic transfer: open issues,“ Philosophical Transactions of the Royal Society B, Vol. 364:2241-2251 (2009). [75.] Anouk Courseaux and Jean-Louis Nahon, “Birth of Two Chimeric Genes in the Hominidae Lineage,” Science, Vol. 291:1293-1297 (February 16, 2001). (nahoru)