
Z odborné literatury vybral Pavel Kábrt – 11/2017
Darwin stavěl na mýtu zvaném pangenesis
Po většinu dějin lidstva jsme nevěděli, co způsobuje odchylky v rámci téhož druhu ani jak se tyto odchylky předávají z jedné generace na druhou. Až do konce 19. století zastávala většina lidí názor, že znaky nového organismu se dědí jako směs rodičovských znaků. To znamená, že potomci jsou kombinací či průměrem obou rodičů. To dávalo v některých ohledech smysl – je snadné zjistit u mnoha dětí podobné znaky obou rodičů. Ale nevedlo by to nakonec k tomu, že by se časem všechny znaky sblížily natolik, že by se přestaly lišit? Lidé tento problém znali, ale nic lepšího je nenapadalo.
V době Charlese Darwina nebylo o genetice známo vůbec nic. Jeho představy o evoluci se tedy vyvíjely jen v prostředí plném spekulativních názorů a fantazií. Darwin přišel s vlastní teorií zvanou pangenesis1. Představoval si jakási ´tělíska´ (gemule – pangenetická teorie) produkovaná různými orgány těla jako odpověď na podněty prostředí. Tato tělíska pak měla doputovat ke gonádám, kde měla být uchována do doby předání další generaci. Tento názor se však neopíral o žádný fyzikální či experimentální základ. Kromě toho se přímo odvolával na starší teorii zvanou lamarckismus čili lamarckovská dědičnost. Jean-Baptiste Lamarck (1744-1829) učil, že jedinec odpovídá na okolí tím, že se například stává silnějším, vyšším, vidí lépe do dálky či je schopen odolat nadměrnému horku. Jedinec pak předává tyto nově získané znaky svému potomstvu, které se pak prý rodí trochu silnější, vyšší atd., než byli jeho rodiče. Takové pojetí bylo nazváno „dědičností získaných vlastností“.
Darwin se tím určitě inspiroval2, ale šlo o omyl, který byl později vědecky vyvrácen. Přesto na tom založil mylnou teorii evoluce, která už nebyla, ani po nových poznatcích vědy, které ji zcela vyvrátily, opuštěna. Lidé si ji oblíbili, zamilovali se do ní jako do náhradního náboženství.

Gregor Mendel. Foto: www.lindahall.org
Nejpodivnější věcí na Darwinově teorii pangeneze je ale to, že byla zveřejněna (1868) bezprostředně poté, co otec moderní genetiky Gregor Mendel objevil zákony genetické dědičnosti (poprvé zveřejněno roku 18663). Na základě své samostatné práce, kterou prováděl v klášterní zahradě, Mendel zjistil, že se mnoho rysů vyskytuje ve vymezených jednotkách (bílé či nachové květy, žlutá či zelená semena atd.), přičemž se každá z variant nazývá alela. Stanovil také, že každý jedinec disponuje dvěma alelami pro každý rys (např. bílý+bílý, nachový+bílý či nachový+nachový) a že každý rodič předává potomkům jen jednu kopii od každé z nich. Potomci tedy nejsou průměrem (směsí) rodičů, nýbrž kombinací nespojitých rysů, které rodiče předávají dětem. Mendel byl sice mnichem, ale věda mu nebyla cizí – měl univerzitní vzdělání ve fyzice i filozofii. V jeho době byla totiž ´církev´ místem, kde se lidé vědě tradičně hodně věnovali. O tom svědčí Darwinovo teologické i vědecké vzdělávání v Cambridge4 jako příprava na dráhu venkovského faráře (čemuž se vytrvale bránil).
Je kuriózní, že Darwin měl potřebné nástroje úplně stejné jako Mendel, měl k dispozici více času, a patrně si také dovedl opatřit pro svou vědeckou činnost více peněz. Přesto však nevypracoval nic, co by jen alespoň připomínalo moderní genetickou teorii. Darwin velmi pečlivě popisoval genetickou pestrost i dědičné vzorce četných druhů rostlin i zvířat, všiml si dokonce při jedné příležitosti i Mendelova slavného poměru 3:15 mezi divokým typem a typem recesivním u dvojitého křížence6. Na tato témata napsal Darwin četné studie i články7. Pročpak tedy neobjevil genetiku? V tom nebudeme mít úplně jasno nikdy, ale Darwin chtěl mít druhy neomezeně proměnlivé, a tomuto přesvědčení se plně odevzdal. Předpokládal, že se neustále rozšiřují nesčetnými vzájemně se propojujícími články s neomezeným rozsahem do minulosti. Tato utkvělá představa jej zavazovala k pátrání po neustálém šíření znaků, až ho to dovedlo k teorii pangeneze a odvolávání se na lamarckismus (později vyvrácený). Geny však nekódují míru rozšíření. Kódují diskrétní znaky. I když platí, že k vytvoření mnoha znaků dochází díky přídavným účinkům mnoha různých genů (což působí mylným dojmem spojitosti); toto právě komplikuje vztah mezi prostředím a rolí genů. Avšak Darwin se díval špatným směrem. Mendel byl experimentátor a došel ke správné odpovědi. Darwin byl spekulant, a pravdu minul zřejmě proto, že se zaměřil jen na filozofické úvahy8.
Nejen Darwin – nepostřehla to ani většina lidí té doby. I Mendelovy myšlenky získaly popularitu teprve za několik desetiletí (darwinisté se genetice nejprve bránili). Darwin ani za celý svůj život nezjistil základní procesy, které jsou pro opodstatněnost evoluční teorie nezbytné. Ukazuje se, že zákony genetiky nejsou k evoluční teorii přátelské.
Genetika v současnosti
Na počátku 20. století začínalo studium genetiky nabírat obrátky. Bylo zjištěno, že se u živého tvora mohou náhle objevit zcela nové znaky zvané mutace, a znovu se začala studovat Mendelova práce. Po určitém úsilí byly po roce 1920 mutace, přírodní výběr a genetika spojeny v evoluční teorii do tzv. moderní syntézy. Dědění pouhé směsi znaků, pangeneze i lamarckismus, byly opuštěny ve prospěch tohoto nového pojetí, které je i po nějakých 150 letech prakticky totožné s názory většiny dnešních evolucionistů.
V první polovině 20. století práce na poli genetiky pomalu přibývalo, až zde v 50. letech došlo k explozi. Roku 1952 Hersheyho a Chaseho slavný pokus prokázal, že nositelkou dědičnosti je DNA (už předtím sice o tom jisté důkazy existovaly, ale mnoho lidí si i nadále myslelo, že tuto práci dělají proteiny). V roce 1953 Watson a Crick objevili, že DNA má tvar dvoušroubovice. V roce 1958 pokus Meselsona a Stahla ukázal, že ony dva řetězce DNA jsou oddělovány a kopírovány nezávisle. Brzy nato byl dešifrován proteinový kód a zjistili jsme, že jednu aminokyselinu v proteinu kódují tři písmena DNA.
Byly tak položeny základy moderní genetiky. V následujících desetiletích bylo vyvinuto sekvenování genů, které bylo později zautomatizováno. Na přelomu tisíciletí se nám rychle otevíraly nové obzory, neboť roku 2003 zveřejnil Projekt lidského genomu přepis asi 93 % lineárních řetězců DNA přítomných v jádře lidské buňky. Šlo o odvážný počin co do šíře záběru i finanční náročnosti: nasekvenování zhruba tří miliard písmen DNA stálo americké daňové poplatníky více než tři miliardy dolarů. Onen monumentální (a drahý!) počin změnil vše. Dnes, díky rychlému rozvoji těchto technologií, existují společnosti, které dokáží snadno nasekvenovat každý den ekvivalent několika lidských genomů, každý z nich za pouhých pár tisíc dolarů; za několik málo let budou však i podobné výkony překonány. Technologický pokrok umožňuje v rychlém tempu nové objevy a tlak na změny mnoha našich tradičních představ roste.
Informace jsou uchovávány v DNA
Přežití a reprodukce veškerého života závisí na specifických informacích (jakési sadě pokynů). Většinu těchto informací kóduje DNA – molekula, která jako médium pro uložení informací nemá sobě rovné. Do pouhého malého kousku DNA lze vložit úžasné množství pokynů. Vezměte si tištěnou stránku. Každé písmeno na ní je vysoké asi tři, čtyři milimetry a na běžné stránce textu je několik tisíc písmen. Kdybychom vytiskli lidský genom jako text a vyrobili z něho vázané knihy velikosti Bible (podle toho, o jaký překlad jde – v průměrné anglické Bibli je 3,5 milionu písmen), muselo by jich být 850. A jelikož dědíte jednu sadu od matky a druhou od otce, obsahuje každá buňka vašeho těla dva exempláře genomu (s výjimkou červených krvinek, které nemají jádro). Písmena DNA jsou však velká pouze několik miliardtin metru. Při této velikosti by se všechny tři miliardy písmen snadno vešly do něčeho mnohem menšího, než je tečka na konci této věty. V buňce jsou písmena seřazena v řetězcích (chromozomech), které by rozvinuté od jednoho konce ke druhému byly dlouhé zhruba 2 m. Tyto dlouhé, křehké, přilnavé řetězce jsou sbaleny do jádra o průměru pouhých 6-10 μm (miliontin metru). Kompletní sada pokynů pro stavbu a udržování člověka je uskladněna v něčem tak malém, že to bez mikroskopu neuvidíte!
Tyto řetězce však nejsou příliš stabilní. Jednovláknová DNA má tendenci se lámat. V jádře buňky tvoří každé vlákno dvojici s vláknem komplementárním, přičemž se obě kolem sebe ovíjejí a vytvářejí tak klasický tvar dvoušroubovice. Jednotlivým úsekem DNA jsou vlastně dvě samostatné, ale komplementární molekuly svázané elektrostatickými interakcemi. Tři miliardy písmen DNA v lidském genomu se nacházejí ve 23 oddělených chromozomech délky asi od 50 milionů do asi 250 milionů písmen. Ani v tomto uspořádání není však DNA příliš stabilní. Je stále nesmírně náchylná k rozkladu a odhaduje se, že v běžné buňce dochází denně až k milionu ´lézí´ DNA (např. ke zlomu vlákna, poškození vlivem záření či ke zničení jednotlivých bází při jejich reakci s kyslíkem)9. A ve vašem těle je zhruba 100 bilionů buněk! Představte si to úsilí, které musí denně vynaložit každá buňka k tomu, aby zachovala svou DNA úplnou. A teď onu práci vynásobte. Kolik je 1 000 000 x 100 000 000 000 000? Tolik práce je třeba, aby si váš genom udržel svou funkčnost v těle, den co den.
Křehkost DNA je jedním z mnoha problémů pro evoluční teoretiky. Aby mohla DNA fungovat, potřebuje celou sadu dodatečných reparačních enzymů, které její funkčnost udržují. Existuje mnoho různých způsobů, jak může být DNA poškozena a existují specifické skupiny enzymů řešících ten který druh poškození. Ale co ještě více zpochybňuje evoluční model je fakt, že ony enzymy kóduje rovněž DNA a zároveň platí, že bez nich by DNA v buňce nepřežila. To je tedy problém vejce a slepice par excellence! Tyto enzymy jsou také citlivé na změny. Mutace v reparačních a kopírovacích enzymech DNA vedou často ke katastrofě. Jak tedy mohly tyto enzymy vznikat postupem času procesem mutací a přírodního výběru? Bez nich nemůže život existovat, a přece musel život vzniknout bez nich a musel začít používat DNA ke skladování informací dříve, než se vyvinul její servisní aparát. DNA je poslední věcí, o které by se kdy mohl člověk domnívat, že ji raný život začal používat ke skladování informací.
DNA jako informační centrum
Uspořádání nukleotidů v molekule DNA má všechny znaky na informace bohatého sdělení.10,11 Sdělení může být předáno, ale v reálném světě nedostaneme sdělení bez odesílatele. Největší záhadou života pak není složitost molekul, na kterých život závisí (i když i tohle je obrovská záhada). Není jí složité uspořádání součástí, které živé organizmy využívají (i když také toto je další obrovská záhada). Nikoli, největší záhadou života je původ informací, na kterých je život založen, a ty se předávají z generace na generaci živých organizmů.
Uchování informací nefunguje bez téměř dokonalého systému jejich údržby a oprav. A přece, navzdory úžasným systémům oprav DNA v lidském těle, nasbíráme za jednu generaci zhruba 100 nových mutací na osobu12. Odhaduje se, že na každé buněčné dělení připadá od jedné do tří mutací13. To není špatná chybovost na ty malé molekulární strojky určené k rychlému zkopírování DNA těsně předtím, než se buňka rozdělí, ale pomyslete na to, kolik buněčných dělení je třeba, aby vznikl člověk; nesete si nyní všechny možné mutace nesčetněkrát, a jejich počet časem jen narůstá. Protože se tedy tyto chyby časem hromadí, odhaduje se, že 60letý člověk má 40 000 mutací v každé buňce výstelky střevního traktu.14 Pokud tedy pomineme úrazy a nemoci, povede už jen toto neúprosné hromadění chyb ke smrti nás všech.
Naštěstí vymyslel stvořitel (Bůh) skvělý mechanismus chránící lidstvo před účinky těchto mutací. Když je vajíčko oplodněno, zygota prochází omezeným počtem buněčných dělení, než se zformují buňky pro příští generaci. U dítěte ženského pohlaví je to do dokončení vývoje vaječníků jen 23 buněčných dělení. Vajíčka ve vaječnících jsou pak živena a chráněna až do ovulace, někdy o 40 či více let později, aniž se jakkoli dále dělí. Většina lidí to neví, ale když žena nosí dítě ženského pohlaví, jsou zde zároveň přítomny tři generace: maminka, děvčátko a vajíčka v jeho nedávno utvořených vaječnících. U mužů se však věci mají trochu jinak. Dítě mužského pohlaví projde v lůně asi třiceti buněčnými děleními, než se vytvoří jeho rozmnožovací buňky, ale ty se začnou na počátku puberty rychle dělit a dělí se, dokud muž nezemře. To by znamenalo, že otec by ve svém vyšším věku předal dítěti více mutací než dítěti, které má zamlada15.
Ne příliš rozsáhlé studie mutací předaných rodiči dětem však ukázaly některé překvapivé výsledky. Zjistilo se, že počet mutací nasbíraných od toho kterého rodiče se může značně lišit, přičemž někdy jich víc dostane dítě od otce a někdy od matky16. To zpochybňuje standardní modely genetických dějin člověka, které předpokládají molekulární hodiny o stejné mutační rychlosti během času a v celém geografickém rozložení populace. O důsledcích těchto zjištění budeme diskutovat dále.
I když většina těchto mutací nevede ke katastrofě (jinak bychom už byli všichni mrtví), jsou přece jen nežádoucí. Genetikové je s oblibou nazývají mírně škodlivými mutacemi a jejich hromadění v lidském genomu je opravdovou výzvou pro evoluční teorii17. Jde o škodlivé mutace a přibývá jich tempem rychlejším, než jakým je teoreticky může přírodní výběr odstraňovat. Ve skutečnosti může přírodní výběr ´zahlédnout´ jen ty nejhorší mutace. Takže evoluce jde nazpět – není s to zabránit pomalé degradaci informací nutných pro život. Je-li tomu tak, pak vyvstává především otázka, jak mohly ony informace vůbec vzniknout? A jak mohly druhy přežít všechny ty miliony let, aniž vymřely? Hovoříme o genetické entropii.
Dříve „odpadní“ DNA, dnes důležitý systém!
Už celá desetiletí slyšíme onu obehranou písničku. Zní asi takto: „Jen 2 až 3 procenta lidského genomu jsou funkční. Zbytek je bezcenná, odpadní DNA – zmetky zbylé z našeho evolučního dědictví.“ Ačkoli nedávné objevy prokázaly, že je tento názor mylný, je i nadále běžně zastáván. Pročpak tedy o něm slýcháme tak často a tak dlouho? To proto, že biologická evoluce potřebuje odpadní DNA k tomu, aby vyřešila velký matematický problém.

Dr. DeWitt: „Odpadní“ DNA není odpadní. Foto: answersingenesis.org
Koncem 50. let 20. století prokázal slavný populační genetik J. B. S. Haldane, že přírodní výběr nemůže v žádném případě vybrat miliony přínosných mutací ani za celou dobu evolučních dějin člověka. Naopak, a to i přes několik zjednodušujících předpokladů ve prospěch evoluční teorie18, by bylo možno od dob našeho společného předka se šimpanzi vybrat pouze pár set přínosných mutací19. Tento závěr se začal označovat Haldaneho dilema, a přestože se leckdy tvrdí opak, nebylo toto dilema nikdy vyřešeno20. Místo toho jsou nám předkládány výplody evolucionistické představivosti. Koncem 60. let 20. století přišel Kimura s myšlenkou neutrální evoluce21. Uvažoval, že pokud je většina DNA v buňce nefunkční, nebude během doby ani mutovat. Organismus by tedy nic nevynakládal na zachovávání těchto nefunkčních částí (tyto „náklady“ se měří podle toho, kolik dětí se musí narodit v populaci navíc, aby mohly být přírodním výběrem zabity a odstranily se tak během času škodlivé mutace při zachování zdatnosti populace,22 samozřejmě za předpokladu, že přírodní výběr dokáže tyto škodlivé mutace rozeznat).
Ohnovi se připisuje zavedení termínu odpadní DNA zhruba o čtyři roky později.23.Myšlenka odpadní DNA je pro evoluční matematiku neobyčejně důležitá. Co by se stalo, kdyby vyšlo najevo, že taková věc neexistuje? Co by se stalo, kdyby namísto 97 % odpadního genomu to byl z 97 % genom funkční?
Moderní technologie dnes koncept odpadní DNA zlikvidovala, a to po dokončení Projektu lidského genomu. Avšak i předtím už bylo zřejmé, že koncept je jasným omylem, ale zdálo se, že zavržení teorie odpadní DNA čelí tvrdošíjnému odporu. Existuje mnoho důvodů, proč dnes věříme, že většina DNA v buňce je funkční. Například byly nalezeny funkce pro mnoho retrotranspozonů24, o nichž se dříve soudilo, že jsou částmi virů, které se během milionů let zabudovaly do našich genomů.
Funkce byly také nalezeny pro mnoho rozsáhlých úseků DNA nekódující proteiny, které se nalézají mezi geny. Ukazuje se, že většina genomu je aktivní. Projekt ENCODE byla studie prováděná mnoha univerzitami, trvala mnoho let a stála mnoho milionů dolarů – jejím cílem bylo zjistit, kolik z lidského genomu je přepisováno (převáděno do RNA, míra funkčnosti). V rámci této studie bylo analyzováno pouze 1 % genomu, ale byly do ní zahrnuty jak oblasti DNA kódující proteiny, tak ´odpadní´ DNA. Bylo prokázáno, že kterékoli dané písmeno genomu je užito průměrně v šesti různých transkriptech RNA.25 To zdaleka neznamená, že se všechno mění na proteiny. Rovněž to neznamená, že má všechno svou závaznou funkci nebo dokonce, že jsou písmena užívána často. Co to však znamená je, že téměř každé písmeno něco dělá. Jelikož základní zákon biologie říká, že po funkci následuje forma, proto fakt, že jsou tyto oblasti aktivní, svědčí do značné míry o tom, že mají funkci. Proč by jinak umožňovala buňka tolik přepisu? Významná část buněčných zdrojů je vynaložena na tvorbu RNA nekódující proteiny. Buňka by tedy značně vydělala na tom, kdyby toto plýtvání energií zastavila. Přírodní výběr trvající miliony let by tuto parazitickou produkci RNA zrušil. Neučinil tak, protože je to nutné pro fungování buňky. Nyní tedy můžeme považovat genom za RNA počítač (viz dále).
Celkové chybění odpadní DNA je opět jedním velkým problémem evoluční genetiky, neboť bez ní nefunguje evoluční matematika. A to se přitom stále nacházejí další funkce pro DNA nekódující proteiny. Opravdu to vypadá, že je ´odpad´ aktivnější než ´geny´, což staví na hlavu starou představu, že jsme organizmy založené na proteinech. Slovy evolučního biologa J. S. Matticka:
- Neschopnost rozpoznat veškeré důsledky tohoto faktu – zejména možnost, že mezilehlé nekódující sekvence mohou předávat paralelní informace ve formě molekul RNA – se může docela dobře v budoucnu ukázat jako jedna z největších chyb v dějinách molekulární biologie26.
Genom je víc než superpočítač
Studenti biologie se v minulosti vždycky učili hypotézu jeden gen, jeden enzym. Na základě úžasných objevů v průběhu 20. století to svádělo k závěru, že ´gen´ je kouskem DNA, který kóduje konkrétní protein. ´Gen´ měl specifický počáteční a konečný úsek, sekce, které kódovaly protein (exony), eventuálně pár mezilehlých sekvencí (intronů), které bylo třeba vystřihnout před translací ´genu´ v protein z primárního transkriptu RNA, a tak pokračujeme vzhůru a dolů regulačními oblastmi, kde se na DNA mohly navazovat další věci a řídit expresi ´genu´. Bylo snadné procházet ´genem´ a vidět tato místa. Bylo možno dokonce překládat DNA do proteinu letmo ze sekvence řetězce informační RNA (mRNA), pokud byly známé třípísmenné kódy pro všechny aminokyseliny (což není až tak obtížné). S hypotézou „jeden gen, jeden enzym“ je však spojen velmi vážný problém, a jako Darwinova myšlenka pangeneze a představa o existenci odpadní DNA, je i tato hypotéza stejně tak mylná.
Zvláště výsledky projektu ENCODE umožnily světu nahlédnout do nejpropracovanějšího počítačového operačního systému ve známém vesmíru – lidského genomu. Není to proteinový počítač. Genom ve skutečnosti připomíná spíše superpočítač na bázi RNA, který produkuje protein. Podobně jako váš počítač, který má pevný disk, operační paměť (RAM) a obrazovku, kde se zobrazují výsledky, má genomický počítač DNA pro ukládání informací, RNA pro porovnávání a propočítávání informací a protein jako výstupní produkt.
Byly podniknuty pokusy porovnat genomické kontrolní procesy s počítačovými systémy vytvořenými lidmi.27 Paralely mezi oběma jsou zajímavé, leč rozdíly jsou zarážející. Například v porovnání s počítačovým operačním systémem Linux má genom bakterie E. coli méně regulátorů na vysoké úrovni, které zase kontrolují méně manažerů na úrovni střední, ti však kontrolují daleko více výstupů na nízké úrovni. Vypadá to, jako by byl bakteriální genom optimalizován tak, aby vykonával svoji práci co nejefektivněji. Místo Linuxu by tak bylo lepší srovnávat ho s vojenskými počítači, které mají většinou velmi krátké programy s minimem instrukcí. Je tomu tak proto, že jsou navrženy k plnění jen omezené sady úkolů co nejefektivněji, místo aby prováděly naráz mnoho různých věcí (jako třeba simultánní využívání grafiky, her, hudby i textového editoru, které umožňuje Linux). Je tu však ještě jedna záhada: člověku trvalo mnoho hodin, než navrhl počítače, schopné řídit bombardéry B-52, a přece může jediná chyba v kterémkoli programu kteréhokoli subsystému způsobit katastrofické selhání kontrolovaného systému. Lidský genom je daleko složitější a dokáže odolat tisícům chyb, aniž by se zhroutil. Kontroluje naráz více věcí a je lépe vyprojektován!
Když byl lidský genom dokončen, byli badatelé šokováni, že v něm našli jen asi 23 000 ´genů´28. Již jsme totiž věděli, že počet proteinů, které lidské tělo vyrábí, je mnohonásobně vyšší. Jak je to možné? O pár let později jsme díky projektu ENCODE získali téměř jistotu o tom, že v lidském genomu dochází k obrovskému množství náhradních sestřihů29. Dozvěděli jsme se, že všechny části ´genu´ mohou být použity v mnoha různých proteinech30. Tělo umí nějakým způsobem tvořit různé kombinace toho, co jsme považovali za odlišné geny kódující proteiny, a pospojovat je tak, že vytvoří několik set tisíc konkrétních proteinů. A nejen to, ale různé druhy buněk jsou schopné tímto složitým způsobem vytvářet různé proteiny. A to ještě není všechno – jednotlivé proteiny jsou vyráběny v různou dobu a buňky nějak vědí, co mají vyrobit, kdy to mají vyrobit, a za jakých podmínek.31 Existuje cosi, co tento proces kontroluje, a není to nutně v části genomu kódující proteiny32.
V každém ´genu´ je zabudována řada malých kódů. Každý z nich je dlouhý jen pár písmen, ale na počátku i na konci každého exonu i intronu je mnoho takových kódů. Tvoří to, co se nazývá spliceozom – to je část genomu, která řídí složitý proces rekombinace exonů čili genového sestřihu. Složitost spliceozomu, a v podstatě složitost celého genomu všech eukaryot je jenom další záhadou evoluční genetiky. Genom je příliš složitý a ´cílová oblast´ pro mutace je příliš rozsáhlá, aby mohly známé druhy organizmů přežívat milióny let,33 natož aby se vůbec nejprve vyvinuly.
Možná byste rádi věděli, proč dávám v celé této kapitole slovo ´gen´ do uvozovek. Je tom tak proto, že pro tohle slovo už nemáme definici34. Definice se změnila přinejmenším potud, že znamená cosi zcela nového pro všechny organizmy složitější než bakterie. V genetice nastal obrat směrem ke složitosti a jednoduchá stará představa se přežila. Když se od tohoto okamžiku objeví slovo ´gen´, chápejte ho v klasickém smyslu: gen je kousek DNA, který kóduje protein. Jediným problémem u této definice je, že kterýkoli konkrétní kousek DNA by mohl být použit v mnoha proteinech v závislosti na kontextu.
Genom je čtyřrozměrný a neuvěřitelně složitý
Pojďme nyní dál a zamysleme se nad další úrovní komplexnosti. Když se podařilo sekvenovat lidský genom, mysleli jsme si, že také porozumíme tomu, jak genom funguje. To však byla naivní myšlenka. To, co jsme dokázali, bylo pouhé přečtení pořadí lineárního řetězce nukleotidů. Tedy pouze první rozměr genomu, který funguje nejméně ve čtyřech rozměrech. Co to znamená? Podívejme se na DNA. Je to řetězec, vlákno, které je svou podstatou jednorozměrné. Když byla dokončena práce na lidském genomu, zdálo se, že teorii o odpadní DNA podporuje fakt, že se geny nalézají roztroušeně po celém genomu a neshlukují se k vykonávání podobných funkcí. „Aha“, říkalo se, „uspořádání genů je náhodné, je výsledkem náhodných změn během doby.“ Avšak to bylo poněkud krátkozraké, neboť jsme to viděli pouze v jednorozměrném pojetí.
Dozvěděli jsme se teď o alternativním sestřihu. V něm jedna část genomu ovlivňuje jinou část, buď přímo či prostřednictvím zástupců v RNA a/nebo proteinech. To je součást druhého rozměru genomu. Kdybychom měli tyto interakce znázornit, museli bychom rozepsat genom a nakreslit velkou spoustu šipek z jednoho místa na druhé. K tomu byste potřebovali mnoho listů papíru, které mají dva rozměry (výšku a šířku).
Druhý rozměr genomu je mimořádně složitý a zahrnuje faktory specifity, zesilovače, represory, aktivátory, transkripční faktory, signály acetylovanými histony, signály metylovanou DNA, posttranskripční regulaci RNA, alternativní sestřih a mnoho dalších věcí. To vše hraje hlavní roli v úzké koordinaci a regulaci rozsáhlé sítě jevů, ke kterým dochází jak v jádře, tak v celé buňce. Pořadí v tomto rozměru nemá velký význam, neboť genové regulátory musí kolovat, aby našly své cíle. Přítomnost cíle bezprostředně vedle regulátoru není nutná. Teprve na další úrovni se věci stávají velmi zajímavými.
Třetí rozměr genomu je 3-D struktura DNA v jádru. Na této úrovni nejsou geny namátkově rozmístěny v jádru, ale jsou uspořádány a seskupeny (do klastrů) dle potřeby. Geny, které jsou využity společně v řadách, nemusí být nalezeny jeden vedle druhého na chromozomech, ale jak se chromozomy sbalí, jsou často nalézány jeden vedle druhého ve 3-D prostoru, a jsou často klastrovány poblíž jaderného póru nebo blízko centra transkripce.35
Takže, cosi je drží na místě. Jelikož DNA lze přirovnat k obřímu svazku vlákna, jsou části zasuté uvnitř tohoto svazku, těžko přístupné, ale další části jsou vystaveny na povrchu či ve vnitřních kapsách36,37. Část kódu, která je uložena uvnitř prvního rozměru, ovlivňuje 3-D sbalování DNA, které má zase vliv na vzory genové exprese. Tento třetí rozměr je neobyčejně důležitý38.
Čtvrtý rozměr genomu zahrnuje změny, které nastanou během času v prvním, druhém i třetím rozměru. Chromozomy jsou v jádře v určitém tvaru, ale tento tvar se během vývoje mění, protože různé druhy buněk potřebují různé sady genů i dalších genetických instrukcí. Tvar se může v krátké době změnit, když buňky odpovídají na podněty a rozbalují úseky DNA, aby se dostaly k zasutým genům, a jakmile už gen nepotřebují, úsek znovu zabalí39. Změnami prochází i ´odpadní´ DNA. Například značná část aktivity retrotranspozonů (kterým se jinak říká skákající či pohyblivé/mobilní geny) probíhá při vývoji mozku, kdy se kousky DNA z několika různých tříd (L1, Alu a SVA) kopírují a skáčou v genomu jednotlivých mozkových buněk. To pomáhá různým mozkovým buňkám, aby se diferencovaly40. Také u jaterních buněk se často setkáváme s mnoha chromozomálními duplikacemi. Konečný genom různých tělesných buněk není tedy nutně totožný s tím, který měla oplozená vaječná buňka, když se začala dělit, a tvar genomu se mění od buňky k buňce i v průběhu času. Tyto příklady nejsou nahodilé, nýbrž jde o pečlivě kontrolovanou symfonii genomických změn ve čtyřech rozměrech. Doufám, že to na vás zapůsobilo, neboť genom byl navržen vskutku mistrovským Architektem.

Foto: journals.plos.org
A: obrázek získaný vybarvením chromozomů v buňce lidského fibroblastu různými fluorescenčními barvivy. B: znázornění stejných dat v nepravých barvách. C: 3D rekonstrukce kompletního uspořádání v jádře z různých úhlů. D: počítačový model chromozomové struktury, z Bolzer et al., 2005.
To je všechno neobyčejně složité, ale darwinismus potřebuje mít život jednoduchý. Přírodní výběr musí být schopen využít malé zádrhele způsobené mutací a vybrat ty nejlepší ze stáda či skupiny zvířat. Jakmile jednou nějaký druh existuje, mohl by snad přírodní výběr v omezené míře fungovat, ale může tenhle proces vysvětlit, jak na samém začátku onen druh vůbec vznikl? Těžko, neboť pouhý proces hromadění chyb a výběru by nemohl vytvořit složitý, v několika rovinách provázaný, čtyřrozměrný systém s ohromující mírou komprese dat a pružnosti. A jakmile je onen systém tady, budou ho vážně ohrožovat budoucí náhodné změny zaviněné mutacemi. Taková je situace, ve které jsme dnes. Je hezké si představit malé změny v již existujícím, složitém systému. Použít ony malé změny jako vysvětlení pro původ onoho systému samotného je však totéž jako říci, že k výrobě nejnovějších operačních systémů počítačů nebyla potřeba inteligence. Avšak co do složitosti a efektivity genom daleko převyšuje technologii všech operačních systémů dnešního světa.
Degenerace kodónů
Počítače navržené lidmi operují dodnes se dvěma bázemi, protože tranzistory nám poskytují pouze dvě písmena, se kterými můžeme pracovat (0 a 1, vypnuto a zapnuto) Ale počty z toho vyplývající jsou dokonale jednoduché a my jsme schopni vyrobit složité počítačové čipy, které na tomto principu operují. Na druhé straně genom má 4 báze. Namísto 0 a 1 jsou zde čtyři písmena (A, C, G, a T). Není to nutné, protože tu samou informaci lze vyjádřit v soustavě s jakýmkoliv počtem písmen [ne však jen jednoho]. Proč tedy 4 báze?
Je to zvláštní, ale ke kódování jediné aminokyseliny v proteinu jsou nutná tři písmena. V genomu tyto třípísmenné kodony jsou zřetězeny pohromadě ve skupinách (exony), kdy každá ta skupina produkuje funkční část jednoho nebo více proteinů. V lidských proteinech se používá 20 aminokyselin, ale existuje 64 možných kodonů (čtyři různá písmena ve třech pozicích umožňují 4x4x4=64 kodonů). Proto některé aminokyseliny, jako alanin, jsou určeny více kodony (GCA, GCC, GCG a GCT). Jiné, jako tryptofan, mají jen jedno přiřazení (TGG). Povšimnete si, že všechny čtyři kodony pro alanin začínají písmeny ´GC´. To znamená, že jakákoliv mutace, která změní poslední písmeno, vyprodukuje stejnou aminokyselinu, i když je ten kodon jiný. Tomu se říká degenerace kodonu a poněkud to přidává na mohutnosti genomu, poněvadž přinejmenším některé mutace v úsecích, kde jsou kódovány proteiny, mají nepatrný čistý efekt.
Řekl jsem ´nepatrný´, protože transferové RNA pro rozličné kodony nejsou v buňce nalézány se stejnou četností. Existují případy, kde změna v jediném písmenu, i když aminokyselina změněna nebyla, způsobila škodlivou mutaci. Při translaci do proteinu došlo k prodlevě, zatímco tRNA byla nalezena ojediněle. To způsobilo, že se protein nesbalil správně a výsledkem byl vadný enzym. Nedávná zjištění ukazují, že proteinová translace může být obecně ovlivněna použitím kodonu, přinejmenším u bakterií, kde rychlost translace závisí na přesně použitých kodonech. Bakteriální buňky se vyhýbají genovým promotorům uvnitř svých genů. Pokud se tam vyskytnou, translace je často dočasně zpomalena, protože bakteriální ribozom má tendenci přilnout k sekvencím promotoru.41 A tak tato možnost alternativních kodonů umožnila Projektantovi navrhnout inteligentně geny tak, aby docházelo k co nejmenším vnitřním konfliktům s jinými genovými rysy.
Kromě tohoto všeho, existuje velmi pádný důvod, proč kodony degenerují, a proč existuje genom o čtyřech bázích. Nejenže jde o optimální způsob, jak kódovat 20 aminokyselin,42 ale je tím též umožněno mnohonásobné překrývání kódů.
Mnohonásobné překrývání kódů
V genomech všech vyšších organizmů existuje velké množství komprimovaných dat. Jakákoliv část každého z těchto genomů může najednou vykonávat několik věcí. Jediné písmeno DNA může být částí exonu, který je střídavě použit dvaceti různými proteiny. Zároveň může být toto písmeno částí kódu pro sestřih, který buňce říká, kdy má ten který z těchto proteinů vyrobit. Toto písmeno může být také součástí histonového kódu. Ten buňka používá k tomu, aby věděla, kde sbalit DNA kolem určitých ochranných proteinů, nazývaných histony. Toto písmeno může také ovlivňovat 3-D strukturu DNA. Může být součástí vše prostupujícího epigenetického kódu, a může být částí třípísmenného kodonu překládaného do určité aminokyseliny. Protože má genom 4 báze a kodony degenerují, Projektant mohl vybrat z alternativních kodonů, aby tak vyřešil četné nároky na simultánnost dějů. Degenerace mu umožnila překrýt mnohonásobné genomické příkazy, aniž by musel snížit nároky na design a jeho požadavky u proteinů.
Mnohonásobně se překrývající DNA a RNA kódy popírají naturalistické vysvětlení a jsou pro přírodní výběr nepřekonatelnou překážkou, protože takto přírodní výběr nemůže působit jako činitel dlouhodobé evoluční změny. Pokud se má selekce vyrovnat s mutacemi, naráží na ´hradbu nepřekonatelných potíží´, které současně ovlivňují více jak jeden znak. Multifunkčnost (nazývaná též pleiotropie) znamená, že určitá mutace může ovlivnit úplně nesouvisející znaky (řekněme třeba barevné vidění, schopnost tolerance vůči česneku a mitochondriální efektivitu, i když toto by už byl extrémní příklad). Toto je opět další velká potíž evoluční genetiky. Jak by mohl jednoduchý proces pokusu a omylu, který hledá vždy tu nejjednodušší odpověď na problém prostředí, vytvořit prokládané a víceúrovňové regulační systémy? Ve skutečnosti je tento systém jedním z divů našeho vesmíru. Bez tohoto víceúlohového (multitáskingového) systému by musel být genom mnohem větší a bez něj by mnohobuněčné organizmy, založené na DNA, nemohly vůbec existovat.
Naše geny svědčí o Genesis
Moderní genetika nám ukázala úžasný svět složitosti. Ale to ještě není všechno, co umí – genetika nám také dává schopnost testovat historické teorie. Existuje-li tolik různých mýtů o stvoření, překvapilo by vás, že právě jeden z nich se s tím, co jsme poznali z genetiky, výborně shoduje? Překvapilo by vás zjištění, že máme v našich genech bohaté svědectví o Stvoření, Potopě a Babylonské věži?

Mechanismus efektu hrdla láhve (bottle-effect)
Protože si Genesis dělá nárok být historickou knihou, a protože tvrdí, že je všeobjímající historií lidstva, přináší také určité konkrétní předpovědi o lidské genetice. Tyto předpovědi pojednávají nejprve o stvoření dvou prvních lidí (Adama a Evy), dále o populačním efektu hrdla láhve, který se udehrál o 1 600 let později za časů Noe (kdy byla celosvětová populace redukována na osm duší), a také o jedinečném rozptýlení lidstva z centrálního bodu na Středním východě o několik set let později. Při zacházení s tímto tématem musíme být opatrní, protože lidská věda, snažící se po staletí dát věci do pořádku, má na svém kontě poměrně dost nelichotivý záznam. Je toho hodně i dnes, v čem se můžeme mýlit.
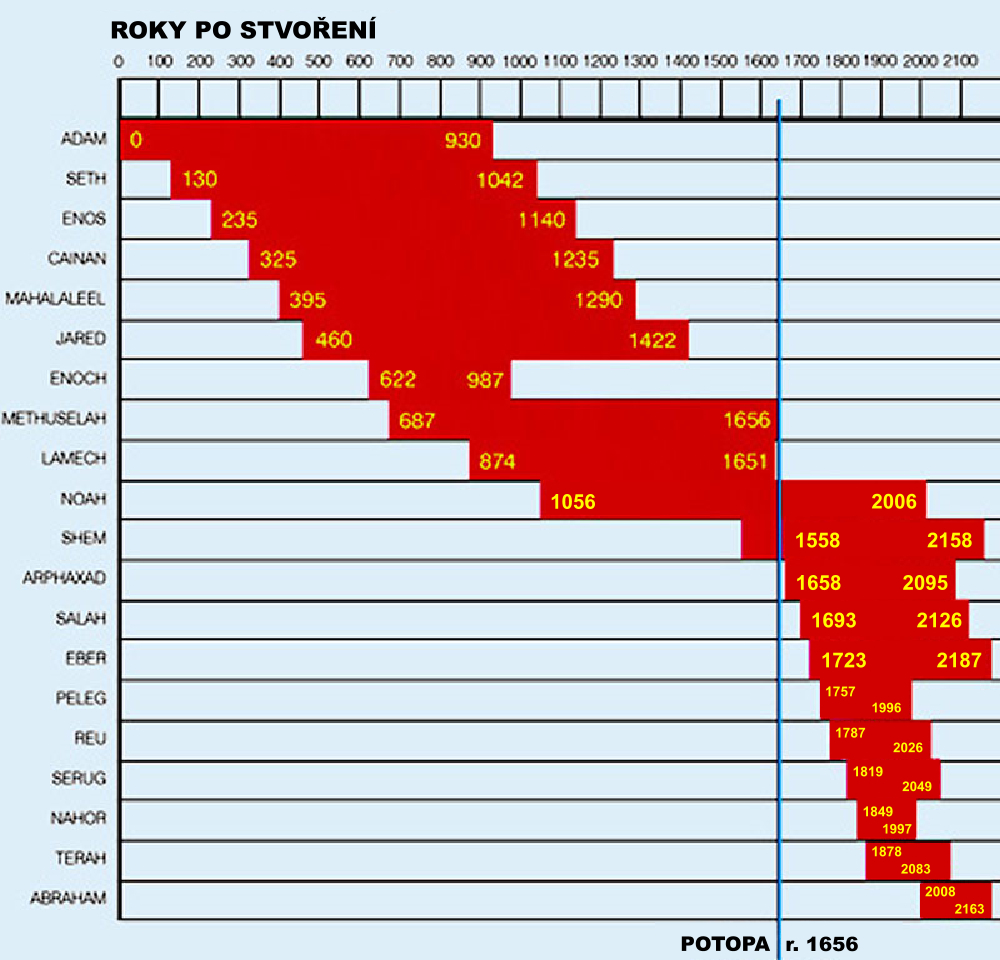
Přehled věku patriarchů podle Genesis. Klikni pro zvětšení.
Nicméně po pečlivé a kritické analýze dostupných údajů může člověk snadno rozpoznat biblický příběh v našich genech. Třebaže lidé jako Francis Collins (vedoucí Projektu lidského genomu, hlásící se k evangelickému křesťanství) tvrdí, že není žádný důkaz o Adamovi a Evě,43 spíše to vypadá, že tito lidé o významu biblických prognóz málo přemýšleli. Bible říká, že veškeré lidstvo pochází z jednoho páru. Toto je základní výrok, týkající se genetiky, neboť tvrdě omezuje velikost genetické rozmanitosti, kterou bychom dnes mohli najít. Nenechme se však ovlivnit evolučním myšlením, které zvažuje pouze takové modely, které počítají s progresí zpět do nekonečna.
Každý člověk po Adamovi a Evě musí být s těmito prvními lidmi spojen normálním procesem sexuální rekombinace a reprodukce, což nemusí nutně platit i pro zakládající pár. Bůh mohl vytvořit mnohočetné buněčné linie v Adamových varlatech. Podobně mohl předem naprogramovat Eviny vaječníky s mnoha lidskými genomy, hodně se lišícími jeden od druhého. Prvotní populace mohla vykazovat pozoruhodně velkou pestrost. Nebo také mohl existovat jen jeden původní genom a Eva by byla prostým klonem (bez chromozomu Y), zřejmě jen haploidní klon Adama. Biblické modely lidské genetické historie mají tak mnoho alternativ. Kterou bychom měli vybrat?
Z teologických důvodů dávám přednost tomu, že Eva byla Adamovým klonem. Tím upadla pod kletbu Boží vztahující se na Adama a jeho potomky, a Eva je spojená s Kristem, příbuzným vykupitelem.44 A také protože byla vytvořena ze žebra vyňatého z Adamova boku, můžeme předpokládat, že pro její vytvoření byly použity buňky, svaly, nervy, krevní cévy a DNA (!) z Adama. Toto z Bible nějak závazně neplyne, mohou být i jiné možnosti, ale tomuto jsem nakloněn.
Možná budete překvapeni, zvláště pokud jste slyšeli nebo četli Francise Collinse, ale rozsah genetické odlišnosti, který dnes pozorujeme, velmi dobře padne na Adama a Evu. Vlastně ta podstatná část padne jen na samotného Adama! V lidském genomu je okolo 10 000 000 míst nesoucích běžné variace. Průměrný člověk jich nese asi kolem dvou nebo tří miliónů. To znamená, že existuje kolem tří miliónů míst, kde jsou sesterské chromozomy v odpovídajících si lokusech čteny odlišně (chromozomy přichází v párech; například od chromozomu 1 máte dvě kopie). Nejde o přehánění, když uvažujeme, že Adam nesl téměř všechny tyto běžné varianty ve svém genomu. Proč si lidé nesou jen podmnožinu z celku? Je to zřejmě důsledek rekurzivity v jejich rodinných stromech. Což znamená, že zdědili identické kopie různých úseků genomu rozličnými liniemi od toho samého vzdáleného předka. Když k tomu přidáme procesy populačního růstu, zúžení, druhotné členění a promíšení během biblických dob45, pak nepotřebujeme žádné milióny lidí, které by žily v dávných dobách, abychom vysvětlili současnou lidskou genetickou variabilitu.
S tím souvisí fakt, že většina běžných genomických variant přichází ve dvou verzích. Pokud najdeme více než dvě verze, lze to vysvětlit dávnou mutací (např. běžná verze krevního typu [skupiny] 0 je evidentní mutací [pokaženou kopií] genu, který kóduje alelu krevního typu A,46 a tento typ je rozšířen po celém světě), nebo jde o mutací, ke které došlo až po Babylónu (jako např. gen pro srpkovitý tvar buňky běžný v určitých částech Afriky, nebo alela pro modré oči běžné v severní Evropě, nebo mnoho variací nalézaných v určitých genech imunitního systému, které jsou navrženy tak, aby se rychle měnily). Protože tedy většina variací spadá do jedné osoby, není nutné navrhovat neobvyklé modely pro dávnou biblickou genetiku.
V případě modelu „Z Afriky“ evolucionisté říkají, že lidstvo si prošlo téměř vyhlazením v důsledku efektu hrdla láhve – dříve, než se naše populace rozšířila a nakonec opustila Afriku. Proč je efekt hrdla láhve součástí jejich modelu? Protože se snaží vysvětlit nedostatek rozmanitosti [diverzity] mezi lidmi rozšířenými po světě.47 Tato rozmanitost je mnohem nižší, než původně předpokládali na základě představ o velké populaci lidí, která žila v Africe milión let či tak nějak. Efekt hrdla láhve je takový podivný ad hoc přílepek k evoluční teorii, zatímco nízká odlišnost mezi lidmi je součástí kreačního modelu od samého počátku.
Trochu odbočím, ale není bez zajímavosti, jak různá jsou v tomto směru zvířata. Ve srovnání se zvířaty jsou lidé výjimečně stejní. Šimpanzi jsou pět až šest krát více rozdílní. Běžná myš domácí má ve své populaci ohromné variace, včetně mnohočetných chromozomálních přeskupení. Ve zvířecím světě je toto velmi hojné. Některé tyto věci jsou důsledkem degradace genomu během času. Něco z toho je také důsledek různých výchozích začátků zvířat ve srovnání s lidmi. Bible neříká, že Bůh od každého druhu živočicha stvořil po dvou. Vlastně můžeme předpokládat, že Bůh stvořil fungující celosvětovou ekologii včetně vysoké rozmanitosti (jak dokládá i záznam zkamenělin) od každého druhu. Je pravda, že na Noemově arše byli jen dva jedinci od většiny druhů, ti však byli vybráni z potenciálně mnohem většího genofondu než lidi. Protože genomická data, která jsou dnes k dispozici, jsou (z pochopitelných důvodů) ponejvíce z lidské populace, jsme hodně daleko od možnosti vybudovat model genetické historie většiny živočišných druhů. Avšak je to zajímavá věc ke zvážení.
Kromě počtu běžných variací, které nacházíme v lidském genomu, existuje stejně tak nevyslovený počet ojedinělých variací. Tyto variace mají sklon vyskytovat se pouze v izolovaných populacích a ukazují na mutace, které nastaly od Adama, vlastně od Babylonu [od babylonského rozptýlení]. Patří k nim modré oči u evropské populace, srpková anemie v africké populaci a mnoho extrémně zřídkavých variací, které se vyskytnou pouze u jednotlivého kmene, rodiny nebo jedince. Ohromné množství genetických variací máme společných. A z toho plyne, že pocházíme z malé populace v nedávné minulosti. To, co rovnoměrně nesdílíme (variace na úrovni populace) indikuje, že naše genomy jsou v prudkém úpadku, což celosvětově ve všech lidských skupinách znamená velkou rychlost mutací. Více o tom ještě dál.
Když zvážíme úseky DNA specifické pro muže a ženu, lze najít ještě více dokladů pro Adama a Evu. Podle rozsáhlé teorie i experimentálních dat jsou mitochondrie (ony malé submolekulární elektrárny, které mění cukr na energii) předávány v ženské linii. Protože mitochondrie mají také svůj malý genom, čítající přibližně 16 569 písmen, a protože tento malý genom během času také podléhá mutacím, můžeme ho využít k vytvoření rodinného stromu předků žen celého světa. To bylo v roce 1987 příčinou, že v evoluční literatuře byla prezentována africká mitochondriální Eva.48 Pokud před milióny let existovaly nějaké jiné ženy, jen jedna z nich mohla předat svůj genom všem dnes žijícím lidem.

Když evoluční vědci mluví o „mitochondriální Evě“, odkazují tak vlastně na biblickou Evu. Nikdy to však nepřiznají. Foto: answersingenesis.org
Má se za to, že datum pro mitochondriální Evu je ve stovkách tisíců let před námi – to však pouze za předpokladu, že je uvažována určitá nízká mutační rychlost a společný předek se šimpanzi. Použijeme-li skutečné rychlosti mutací ve světě, dostaneme pro Evu stáří kolem 6 000 let před námi.49 Ještě nedávnější studie ukázaly, že k mutacím v řízené mitochondriální oblasti (což je oblast, na kterou se vztahují přibližně 2/3 všech mitochondriálních mutací) dochází rychlostí jedné mutace na každou druhou generaci.50 Protože Evina mitochondriální sekvence byla rekonstruována a publikována v evoluční literatuře51, a protože většina mitochondriálních linií je menších než 30 mutací odstraněných z ´Eviny´ konsensuální sekvence, a protože těch nejodlišnějších odstraněných mutací je jen 100, odlišnost mitochondriální DNA uvnitř moderní lidské populace snadno zapadá do intervalu 6 000let/200 generací!
O hypotéze africké Evy ve světle evolučních předpokladů bylo zde již pojednáno,52 takže nebudeme opakovat detaily. Známe sekvenci více jak 99 % mitochondriálního genomu původní lidské ženy. O nějaké jiné nejsou doklady. Proč lidé věří, že Eva byla jen jednou z mnoha žijících žen ve velké populaci před velmi dlouhou dobou? Protože toto je součástí modelu evoluční historie. Nevychází to z reality, ale dává to evolucionistům vhodnou záminku nedbat na biblickou předpověď, že na světě bude existovat jen jediná ženská rodová linie.
Podobně jako mitochondriální genom, také mužský Y chromozom nám umožňuje vytvořit rodinný strom všech mužů světa. Adamův chromozom Y rovněž tak zřejmě existoval před dávnou dobou, ale v jiném čase než mitochondriální Eva. Jenže stejně jako bylo uvedeno výše, i tyto závěry jsou založeny na modelech, které mají velmi mnoho předpokladů o lidské historii, velikosti populace a rychlosti mutací. S publikováním revidovaného šimpanzího chromozomu Y53 a zjištěním, že šimpanzí chromozom je jen ze 70 % shodný s lidským chromozomem Y (i toto číslo je příliš velkorysé, protože polovina šimpanzího chromozomu Y chybí), jsou evolucionisté nuceni přijmout závěr, že chromozom Y během lidské historie mutoval extrémně rychle. Jenže ve světě nalezené současné lidské chromozomy Y jsou si navzájem všechny velmi podobné. Jediná možnost, jak si uchovat podobnost při velmi vysoké mutační zátěži, je mít velmi nedávného společného předka. A hle, jasný Adam!
Další možnosti testování věrohodnosti Adama a Evy nám dávají vazební data. Během sexuální reprodukce procházejí buňky obou rodičů meiózou, kde jsou chromozomy zděděné od jejich rodičů společně promíchány. Když pak rodiče předávají svoje geny, předávají ve skutečnosti směsici verzí chromozomů svých prarodičů. Toto smíchání, nazývané překřížení (crossing over), způsobuje, že je DNA děděna ve velkých blocích. Existují úseky genomu, které neprošly v celé lidské historii překřížením (což naznačuje mládí genomu). Když jsou dvě varianty společně zděděny (protože jsou sobě blízko na stejném řetězci DNA), tak se o nich řekne, že jsou svázány. Vazba byla podrobně studována a naučili jsme se zde řadu zajímavých věcí. Předně, mezi dvěma a čtyřmi běžnými úseky leží objasnění většiny úseků z celé lidské populace.54 Jinými slovy, existuje jen několik původních chromozomů a části těchto chromozomů jsou stále nedotčeny. V genomu je jen kolem deseti tisíc úseků – což je snadno vysvětlitelné, pokud je stáří lidské populace pouze okolo 200 generací, a na jednu generaci a jedno dlouhé rameno chromozomu připadají 1-2 události překřížení.
Vedle předpokladu molekulárních hodin – a ten je skryt v převážné části evolučních studií – většina také předpokládá, že rekombinace je během doby a napříč všemi zeměmi stejná. Tak tomu však nemusí být, neboť víme, že překřížení je ovlivňováno genetickými faktory (zvláště genem PRDM9), a že uvnitř těchto faktorů existují variace, ovlivňující rychlost překřížení u různých jedinců.55 To představuje vážnou námitku vůči řadě primárních evolučních studií, včetně mnoha tvrzení o důkazech našeho afrického původu.
Tak odkud – z Afriky nebo z Bábelu?
Když jsme si říkali o mitochondriální Evě, zmiňovali jsme v té souvislosti teorii o africkém původu člověka. Zde si nyní jednoduše vyjmenujeme shodné faktory mezi scénářem ´Z Afriky´ a zprávou v Genesis. Podle nejrozšířenějšího evolučního příběhu pocházíme z malé populace, která se rozdrobila na ještě menší skupiny, což mělo nastat během jediné události lidského rozptýlení po celé Zemi. Toto rozptýlení proběhlo v nedávné minulosti a týkalo se tří hlavních ženských rodokmenů a jednoho hlavního mužského rodokmenu. A hle, než se dostali do Evropy, Asie, Austrálie, Oceánie nebo obou Amerik, museli projít Středním východem. Všechny tyto jednotlivosti byly předpovězeny ve zprávě o Potopě (Genesis 6-8), o Babylonské věži (Genesis 11) a v Tabulce národů (Genesis 9-11). Rozdíl je jen v časování (6 000, 4 500 a ~4 000 let před námi proti desítkám tisíc let před námi), a také ve výchozím místě (Střední východ oproti severní Africe poblíž Rudého moře56). Jenže k závěrům v modelu ´Z Afriky´ se dochází pod vlivem prvotních evolucionistických předpokladů.57 Zkráceně řečeno, oni předpokládají, že fungují molekulární hodiny, což znamená hromadění mutací ve všech populacích stejnou rychlostí po celou dobu.

Světová migrace mtDNA podle zastánců teorie ´Z Afriky´. Foto: www.jeffdonofrio.net
Už jsme viděli, že toto není pravda. Předpokládají, že všechny populace vykazují zhruba stejnou demografii (míru porodnosti i úmrtí, průměrný věk pro sňatky, průměrný počet dětí atd.). Také předpokládají, že nejsou žádné rozdíly mezi populacemi v reparačním mechanismu DNA, protože to by molekulární hodiny pohřbilo. Takže když najdou větší rozdílnost v Africe, automaticky vyvodí závěr, že jde o starší populaci a zdroj původu pro zbytek lidstva. Jenže – co když některé africké kmeny mají jinou genetickou historii než ten zbytek? Existuje mnoho Afričanů, kteří spadají do průměrného světového typu mitochondriální sekvence v genofondu. A jsou jiní, kteří se od nich hodně liší. Znamená to snad, že toto jsou starší sekvence, nebo že tito lidé prostě jen z nejrůznějších důvodů nabrali víc mutací do svého mitochondriálního rodokmene? Jen pro zajímavost – nedávná studie tvrdí, že prvotní africké kmeny zůstávaly malé a jeden od druhého izolované po tisíce let.58 To je recept pro rychlou akumulaci mutací a genetický drift.
Jsou ještě další souvislosti mezi scénářem ´Z Afriky´ a Genesis. O lidech se všeobecně má za to, že v Africe existovali po nějaké milióny let jako Homo erectus. Později tato populace, předcházející moderní lidi, bez jakéhokoliv vysvětlení zkolabovala a téměř vymřela. Deset tisíc nebo i méně přeživších dokázalo vydržet a rychle se vyvinuli v moderního člověka. Populace se vzpamatovala, diverzifikovala, a pak se některým genetickým rodovým liniím podařilo z Afriky uniknout a dobýt svět. Biblická zpráva začíná dvěma lidmi, Adamem a Evou. Populace pak roste až k neznámému počtu a kolabuje, a 1 600 let po stvoření je při Potopě zredukována na osm duší se třemi reprodukčními páry. Poté se populace vzpamatuje, ale lidé pokračují v popírání Boha stejně, jako to dělali ti před Potopou. Proto Bůh zasahuje a mate jejich jazyky na místě zvaném Bábel, což způsobí, že se jednotlivé rodinné klany rozejdou nejrůznějšími cestami. Takže několik generací po Potopě se lidé po neúspěšné stavbě babylonské věže rozptýlí a dobývají svět. Je tu velmi pěkná všeobecná shoda mezi scénářem Z Afriky a Genesis poté, kdy se evoluční příběh přizpůsobí daným faktům. Konkrétně, scénář Z Afriky se musí nějak vypořádat s nedostatkem různosti mezi lidmi po celém světě (proto, že populace zkolabovala), a s jediným rozptylem lidí, což je patrné z našich genů.
Neandertálci nám připravili překvapení
Jak se pak ale postavíme k tvrzením o předchůdcích moderního člověka, kteří žili v jeskyních? Nové objevy v archeologii a genetice během minulých desetiletí donutily evoluční pohledy např. na Neandertálce, radikálně změnit. Dnes se o Neandertálcích věří, že v jeskyních malovali, vytvářeli si hudební nástroje, uměli zacházet s ohněm, pohřbívali svoje mrtvé obřadním způsobem hlavou směrem k vycházejícímu Slunci, pídili se krajinou po zvláštních minerálech, aby je poté rozemleli a udělali z nich kosmetiku.59 O detailech tohoto seznamu se mezi různými evolucionisty stále diskutuje, ale kdyby byla před několika málo lety jen jedna z těchto myšlenek vyslovena (natož několik), rovnalo by se to evolučnímu kacířství.
Díky rychlému technologickému pokroku můžeme nyní získat DNA z některých dobře zachovalých neandertálských kostí. Celá oblast vědy, zabývající se genetikou dávnověké DNA, je problematická, protože DNA je křehká molekula, a po smrti organismu se rychle rozpadá. Některá poškození jsou také podobná těm, ke kterým dochází během času v živých organizmech. Tím je pak obtížné rozlišit rozpadlou DNA po smrti jedince od té, která zmutovala ještě v jeho předcích. Dalším problémem je kontaminace. Protože je DNA ve starém vzorku nevyhnutelně poškozena, jakákoliv kontaminace moderní DNA ještě více zničí důkazy pro starobylou DNA. Výzkumníci jsou si těchto problémů dobře vědomi a udělali velmi mnoho, aby to překonali. Včetně toho, že s každým takovým novým nálezem zachází podobně jako v kriminalistice, tedy pracují v čistých prostorách se sterilní technikou, navrženou k zamezení kontaminace od lidí, kteří s kostmi zacházejí.60
Nyní k tomu, co jsme tedy poznali. Překvapí vás, že genetika naložila na evolucionisty další trápení? Po pečlivém zvážení výše vyjmenovaných položek, přinesly moderní studie genetiky Neandertálců některé překvapující výsledky. Prvně bylo zjištěno, že měli stejný gen (FoxP2), který dává moderním lidem schopnost mluvit.61 Dále vědci zjistili, že někteří Neandertálci měli podobné verze genů pro kožní pigmentaci, způsobující světlou kůži a ryšavé vlasy, dále zelené oči a pihy, jak je nacházíme u lidí evropské rodové linie.62 Všechno svědčí o tom, že Neandertálci byli mnohem blíže lidem, než se kdysi myslelo; pak ale, na základě mitochondriální DNA, získané z neandertálských vzorků, byl učiněn závěr, že se zřejmě nekřížili s předky moderního člověka, protože neandertálské mitochondriální sekvence nejsou v dnes žijících lidech nalézány.63
Tyto závěry však měly krátký život, protože brzy nato byl publikován64 celý neandertálský genom (přesněji 60 % z něj). Pokud jsou sekvence přesné, pak Neandertálec vůbec není tím, co se očekávalo. Nyní máme důkazy, že se křížili s přímými předchůdci moderních lidí, ve smyslu biologického druhu, tedy že patříme s nimi ke stejnému druhu. Ukazuje se, že lidé žijící mimo Afriku mají 3-4 % neandertálské DNA. Je zajímavé, že pozůstatky Neandertálců nebyly v Africe nalezeny, ale stopy jejich genomu stále zůstávají na místech, kde žili (i mimo tato místa). Muselo přijít nové evoluční vysvětlení – modifikovaný scénář Z Afriky, ve kterém docházelo k omezenému křížení mezi moderními lidmi a Neandertálci, když [lidé] opustili Afriku a nahrazovali Neandertálce na své cestě k opanování světa. Tento názor je však odklonem z pevného názoru ještě před nedávnem. Vzpomínáte si, jakou sebedůvěru měli evolucionisté, když tloukli biblické kreacionisty po hlavě svou hypotézou o africkém původu člověka? Mnohé z toho, čemu věřili, není dnes podporováno jejich vlastními daty z vědy.65
Je tu však jiný scénář, který také odpovídá faktům. Místo dvou velkých populací, které se jen stěží mísily (pokud Neandertálská populace byla mnohem menší než hlavní migrační vlna), mohlo spíše docházet ke kompletnímu promíchání se stejným výsledkem. Pokud je moderní neafrická populace ze 3-4 % neandertálskou, pak byla zřejmě jejich populace velikostí jen 3-4 %, nebo někde uprostřed toho, spolu s různým stupněm promíšení. Jestliže to byli lidé, zvláště popotopní populace, pak promíšení by bylo zcela přirozené, protože konec konců lidé dělají to, nač jsou zvyklí. Nedávná data ukazují, že Neandertálci si byli napříč svou skupinou více podobni, jeden druhému, než jsou si podobni jednotliví lidé uvnitř kterékoli jiné moderní skupiny.66 Od Španělska až ke střednímu Rusku vypadají Neandertálci jako jedna rozšířená rodina – lidská rodina – která žila na zemi v Evropě a Asii po Potopě, a která byla později přemožena migrujícími lidmi.
Člověk versus šimpanz
Několik desetiletí jsme slýchávali, že „Lidé a šimpanzi jsou z 99 % identičtí.“ To však není pravda.67 Toto číslo vychází z některých dřívějších experimentálních dat, ve kterých byly navzájem porovnávány úseky známých genů, takže aspoň něco z naší DNA je velmi podobné. Ale naše genomy kódují proteiny z méně jak 2 % a mnoho genů je mezi těmito dvěma druhy neporovnatelných. Lidé mají několik set genů, které kódují proteiny (všechny jsou těsně integrovány ve spliceozomu [jaderné organele]), a které u šimpanze chybí. Existují celé velké genové rodiny, které najdeme u lidí, ale ne u šimpanzů.68 Toto vrhá do evolučních modelů chaos, protože jen před několika málo stovkami tisíc generací jsme údajně ještě byli jedním druhem.69 Jak mohly tyto zbrusu nové geny vzniknout a být integrovány do našich složitých genomů v tak krátkém čase? Čas totiž pro evoluci není v tomto případě rozhodujícím faktorem. Evoluce se měří na generace, a těch právě nebylo dost od předpokládaného společného předka.
Ve skutečnosti existují rozdíly u zhruba 35 000 0000 jednotlivých písmen70; ty musely vzniknout (půlka u každého druhu), rozšířit se v každé z těchto populací a být zafixovány v těchto málo generacích (původní písmeno v daném umístění bylo kompletně ztraceno). Stejně tak muselo dojít k desetitisícům chromozomálních přeskupení, které se musely rozšířit a zafixovat, stejně jako desítky miliónů párů bází inzercí a delecí. Rychlost, se kterou dochází k fixacím, je nízká, a u mnoha nových variant se očekává jejich ztráta (protože z definice samé jsou jen zřídka). Potřebná rychlost mutací a selekce pro takovéto množství změn za pouhých 6 miliónů let je šokující, ale pokud má být evoluce pravdou, pak k tomu muselo dojít.
Nízká podobnost mezi lidským a šimpanzím chromozomem Y už byla výše probírána. Při pouhé 70 % podobnosti mezi jednou polovinou existujícího šimpanzího chromozomu Y, musela být mutační rychlost neobvykle vysoká. Zdá se divné, proč mají muži tak podobné chromozomy Y? Možná proto, že tento chromozom je starý jen 6 000 let!
Očekává se, že lidé a šimpanzi jsou tak nějak podobní. Šimpanzi vypadají podobně jako lidé, podobně se chovají, jedí podobnou stravu a jejich požadavky na prostředí jsou podobné těm našim (až na to, že my jsme byli dost chytří, abychom vymysleli zateplené domy a teplé šaty). Proč by někdo neměl očekávat i podobnost na genetické úrovni? Jenže zkuste si představit reakce evolucionistů, kdyby mezi člověkem a šimpanzem nebyly žádné genetické podobnosti. Tvrdili by, že neexistuje žádný důkaz pro inteligentního stvořitele, protože by přece každý očekával, že stvořitel použije pro podobné organizmy i společné výchozí šablony. Padá panna, evolucionista vítězí, padá orel, kreacionista prohrává!71
Takže, jak jsme si podobní? Slovy známého genetika Svante Pääba:
- Myslím si, že není žádný způsob, jak toto číslo spočítat … v konečném důsledku je to věc politická, sociální a kulturní, jak my sami vidíme naše rozdíly.72
Mutace jsou příliš rychlé
Jak už víme, přírodní výběr není schopen většinu mutací ´vidět´. Závěr je, že většina mutací, ačkoli jsou špatné, proklouzne sítem selekce. To tedy znamená, že se zhoubné mutace v našich druzích hromadí – to je ale pravým opakem toho, co dlouhodobá evoluce potřebuje. Uplatněte tuto myšlenku v souvislosti s moderními znalostmi o složitosti genomu a začnete vidět ohromnou velikost tohoto problému. Eukaryotické genomy (zahrnují vše kromě bakterií) jsou nesmírně složité a cíl pro mutace u eukaryotických genů je příliš velký, než aby mohla evoluce fungovat. Průměrné písmeno je kopírováno do šesti různých RNA transkriptů a používáno ve mnoha překrývajících se kódech (histon, sestřih, protein atd.). Pro evolucionisty se mutace odehrávají závratnou rychlostí, čímž je dán limit celkového trvání lidské rasy. Jedna věc je ale jistá: Ježíš slíbil svůj návrat a to, že až se vrátí, lidé tu stále budou. A tak lidstvo nevymře před jeho druhým příchodem. Kdy to bude? Na základě předpovědi, jak dlouhodobě škodlivý dopad na genom mají mutace, tak jistě ne za milióny let.
Palčivý problém
Genom je multiprostorový operační systém se zabudovanými kódy pro korekci chyb a vlastní modifikaci. Je v něm mnoho překrývajících se DNA kódů, RNA kódů a strukturálních kódů. Jsou v něm DNA geny a RNA geny. Genom byl úmyslně navržen s velkým množstvím redundance [nadbytku informací]. Přes tento nadbytek vykazuje genom úžasný stupeň celistvosti, kdy ~20 000 ´genů´ svými kombinacemi vytvoří >>100 000 různých proteinů. Časem se také genom pomalu rozpadá, přesto však zůstal dodnes životaschopný díky nádherně vyprojektovaným reparačním kódům a zabudované, inteligentně propracované redundanci.
Je všeobecně známý jeden Darwinův výrok:
- Pokud by mohlo být ukázáno, že existuje nějaký složitý orgán, který by zřejmě nemohl vzniknout nesčetnými, po sobě jdoucími drobnými modifikacemi, moje teorie by se naprosto zhroutila.73
I když byl tento citát během let zneužíván (oběma stranami), přesto je zřejmé, že právě touto věcí je lidský genom. Není myslitelné, aby genom vznikl naturalistickými procesy. Evolucionisté by nám měli ukázat přijatelný scénář genomové historie, včetně zdroje informačních změn, rozbor množství potřebných mutací a popis potřebných selektivních sil – a to vše v patřičném časovém rámci. Zatím však nepřišli s žádným mechanizmem, podle něhož by se mohl jakýkoliv genom poprvé objevit, vzniknout bez předchozích instruktážních informací, jen ze startovní nuly tohoto světa.
V genech dnešního člověka je obrovské množství důkazů pro stvoření dvou původních lidí (Adama a Evy), pro populační hrdlo láhve, ke kterému došlo o stovky let později (během Noemovy Potopy), a následné rozčlenění populace o několik generací později (v Bábelu) včetně jedinečného rozptylu lidské populace po celé planetě. Nejen toto, ale i rychlost mutací, jejich rozšíření a křehkost ultrasložitého počítačového operačního systému, kterému říkáme lidský genom – to vše svědčí o mládí této soustavy. Fakta ze současné genetiky svědčí o stvoření, nikoli o evoluci.
Nyní by už mělo být jasné, že genetika není pro darwinismus žádným přítelem. Darwinova neznalost složitosti života, způsobů, jakými se druhy reprodukují a křehkosti složitých systémů – to vše mu umožnilo vytvářet své vlastní teorie o jinak nepřekonatelných překážkách. Darwinismus by měl být hodnocen ve světle moderních poznatků. Moderní genetika velice dobře podporuje biblickou zprávu.
Odkazy
1. Darwin, C.R., The variation of animals and plants under domestication, London, John Murray, 1868; darwin-online.org.uk.
2. Carter, R., Darwin’s Lamarckism vindicated? March 2011; creation.com/epigenetics-and-darwin.
3. For an English translation, see Druery, C.T. and Bateson W., Experiments in plant hybridization, Journal of the Royal Horticultural Society 26:1–32, 1901.
4. His father sent him to study at Cambridge after he dropped (or failed) out of medical school in Edinburgh. After graduating from Cambridge, he went on his famous five-year round-the-world voyage on the Beagle, and never did go on to become a parson.
5. Mendel showed that, when crossbreeding two individuals that both carry a dominant and recessive version of a gene (e.g. dominant purple petals and recessive white petals), one obtains a 3:1 ratio of wild type (purple) to recessive (white). This occurs because the only plants that will have white flowers are the ones that receive two copies of the recessive gene. Thus, ¾ of the plants will have purple flowers and ¼ will have white flowers: a 3:1 ratio of purple to white.
6. Howard, J.C., Why didn’t Darwin discover Mendel’s laws? Journal of Biology 8:15, 2009.
7. Including: The Variation of Animals and Plants under Domestication, 1868; The Effects of Cross and Self-Fertilisation in the Vegetable Kingdom, 1876; and The Different Forms of Flowers on Plants of the Same Species, 1877.
8. Howard, J.C., ref. 6.
9. Lodish, H. et al., Molecular Biology of the Cell, 5th ed., W.H. Freeman and Company, New York, 2004.
10. Batten, D., Book review: The Biotic Message: Evolution versus Message Theory, J. Creation 11(3):292–298; creation.com/biotic.
11. Gitt, W., Scientific laws of information and their implications—part 1, J. Creation 23(2):96–102; creation.com/laws-of-information-1. See also other parts in this series.
12. Lynch, M., Rate, molecular spectrum, and consequences of human mutation, Proc. Nat. Acad. Sci. USA 107(3):961–968, 2010. Similar numbers have come from many other studies, including Neel, J.V. et al., The rate with which spontaneous mutation alters the electrophoretic mobility of polypeptides, Proc. Nat. Acad. Sci. USA 83:389–393, 1986; Nachman, M.W. and Crowell, S.L., Estimate of the mutation rate per nucleotide in humans, Genetics 156:297–304, 2000; Kondrashov, S., Direct estimates of human per nucleotide mutation rates at 20 loci causing Mendelian disease, Human Mutation 21:12–27, 2002.
13. Eyre-Walker, A. and Keightley, P.D., High genomic deleterious mutation rates in hominids, Nature 397:344–347, 1999.
14. Lynch, M., ref 12.
15. Crow, J.F., The origins, patterns, and implications of human spontaneous mutation, Nature Reviews: Genetics 1:40–47.
16. Conrad, D.F. et al., Variation in genome-wide mutation rates within and between human families, Nature Genetics 43:712–714, 2011.
17. Kondrashov, A.S., Contamination of the genome by very slightly deleterious mutations: why have we not died 100 times over, J. Theor. Biol. 175:583–594.
18. ReMine, W.J., Cost theory and the cost of substitution—a clarification, J. Creation 19(1):113–125, 2005; creation.com/cost.
19. Haldane, J.B.S., The cost of natural selection, Journal of Genetics 55:511–524, 1957.
20. Batten, D., Haldane’s dilemma has not been solved, J. Creation 19(1):20–21, 2005; creation.com/haldane. See also saintpaulscience.com/Haldane.htm.
21. Kimura, M., Evolution rate at the molecular level, Nature 217:624–626, 1968.
22. ReMine, W.J., ref. 18.
23. Ohno, S., So much “junk” DNA in our genome, Evolution of genetic systems, Brookhaven Symposia in Biology, no. 23 (Smith, H.H., ed.), pp. 366–370, 1972.
24. Carter, R.W., The slow, painful death of junk DNA, J. Creation 23(3):12–13, 2009; creation.com/junkdnadeath.
25. Birney, E. et. al., Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project, Nature 447:799–816, 2007.
26. J.S. Mattick, as quoted in Gibbs, W.W., The Unseen genome: gems amid the junk, Scientific American, pp. 47–53, Nov 2003.
27. Yan, K.-K. et al., Comparing genomes to computer operating systems in terms of the topology and evolution of their regulatory control networks, Proc. Natl. Acad. Sci. USA 107(20):9186–9191, 2010.
28. Stein, L.D., Human genome: end of the beginni.Nature 431:915–916, 2004.
29. Birney, E. et al., ref. 25; see also Williams, A., Astonishing DNA complexity update, July 2007, creation.com/dnaupdate.
30. Barash, Y. et al., Deciphering the splicing code, Nature 465:53–59, 2010.
31. See Anon., Human genes sing different tunes in different tissues, PhysOrg.com, 2 Nov 2008.
32. Carter, R.W., Splicing and dicing the human genome, July 2010; creation.com/splicing.
33. Lynch, M., ref. 12.
34. Gerstein, M.B. et al., What is a gene, post-ENCODE? History and updated definition, Genome Research 17:669–681.
35. Schoenfelder, S. et al., Preferential associations between co-regulated genes reveal a transcriptional interactome in erythroid cells, Nature Genetics 42:53–61, 2009; See also Scientists’ 3-D view of genes-at-work is paradigm shift in genetics, sciencedaily.com, 16 Dec 2009.
36. Eitan, Y. and Tanay, A., Probabilistic modeling of Hi-C contact maps eliminates systematic biases to characterize global chromosomal architecture, Nature Genetics 43(11):1059–1067, 2011.
37. Is the shape of a genome as important as its content? PhysOrg.com, 29 Oct 2010.
38. Bolzer, A. et al., Three-dimensional maps of all chromosomes in human male fibroblast nuclei and prometaphase rosettes, PLoS Biol 3(5):e157, 2005.
39. See: A new look at how genes unfold to enable their expression, PhysOrg.com, 14 July 2008.
40. Baillie, J.K. et al., Somatic retrotransposition alters the genetic landscape of the human brain, Nature 479(7374):534–537.
41. Li, G.-W., Oh, E., and Weissman, J.S., The anti-Shine-Dalgarno sequence drives translational pausing and codon choice in bacteria, Nature 484(7395):538–541, 2012.
42. For example, in a base-2 system, it would take at least 5 letters to code for 20 amino acids, with less degeneracy (25 = 32 possibilities).
43. Carter, R.W., The non-mythical Adam and Eve: refuting errors by Francis Collins and BioLogos, August 2011; creation.com/biologos-adam.
44. Sarfati, J., The Incarnation: Why did God become Man? December 2010; creation.com/incarnation.
45. Carter, R.W., ref. 43.
46. Sarfati, J., Blood types and their origin, J. Creation 11(1):31–32, 1997; creation.com/blood-groups.
47. Carter, R.W., The Neutral Model of evolution and recent African origins, J. Creation 23(1):70–77; creation.com/african-origins.
48. Cann, R.L., Stoneking, M., and Wilson, A.C., Mitochondrial DNA and human evolution, Nature 325:31–36, 1987.
49. Wieland, C., A shrinking date for eve, J. Creation 12(1):1–3, 1998; creation.com/eve.
50. Madrigal, L. et al., High mitochondrial mutation rates estimated from deep-rooting Costa Rican pedigrees, American Journal of Physical Anthropology 148:327–333, 2012. See also Carter, R.W., Is ‘mitochondrial Eve’ consistent with the biblical Eve? Jan 2013; creation.com/mteve-biblical-eve.
51. Carter, R.W., Mitochondrial diversity within modern human populations, Nucl. Acids Res. 35(9):3039–3045, 2007.
52. Carter, R.W., ref. 43; Carter, R.W., ref. 47.
53. Hughes, J.F. et al., Chimpanzee and human Y chromosomes are remarkably divergent in structure and gene content, Nature 463:536–539.
54. The International HapMap 3 Consortium, Integrating common and rare genetic variation in diverse human populations, Nature 467:52–58, 2010.
55. Parvanov, E.D. et al., PRDM9 controls activation of mammalian recombination hotspots, Science 327:835, 2010; Berg, I.L. et al., PRDM9 variation strongly influences recombination hot-spot activity and meiotic instability in humans, Nature Genetics 42(10):859–864, 2010; See also, Carter, R.W., Does genetics point to a single primal couple? Apr 2011; creation.com/genetics-primal-couple.
56. Tishkoff, S.A. et al., The genetic structure and history of Africans and African Americans, Science 324:1035–1044, 2009.
57. Carter, R.W., ref. 47.
58. Behar, D.M. et al., and The Genographic Consortium, The dawn of human matrilineal diversity, Am. J. Human Gen. 82:1130–1140, 2008.
59. Carter, R.W., The Painted Neanderthal, May 2010; creation.com/the-painted-neandertal.
60. Carter, R.W., Neandertal genome like ours, June 2010; creation.com/neandergenes.
61. Borger, P. and Truman, R., The FOXP2 gene supports Neandertals being fully human, J. Creation 22(2):13–14; creation.com/foxp2.
62. Lalueza-Fox, C. et al., A Melanocortin 1 Receptor allele suggests varying pigmentation among Neanderthals, Science 318:1453–1455, 2007.
63. Green, R.E. et al., A complete Neandertal mitochondrial genome sequence determined by high-throughput sequencing, Cell 134:416–426, 2008; Carter, R.W., The Neandertal mitochondrial genome does not support evolution, J. Creation 23(1):40–43, 2009; creation.com/neandertal-mito.
64. Green, R.E. et al., A draft sequence of the Neandertal genome, Science 328:710–722, 2010.
65. Carter, R.W., Neandertal genome like ours (There may be Neandertals at your next family reunion!), June 2010; creation.com/neandergenes.
66. Reich, D. et al., Genetic history of an archaic hominin group from Denisova Cave in Siberia, Nature 468:1053–1060, 2010. See also Wieland, C. and Carter, R.W., Not the Flintstones—it’s the Denisovans, Jan 2011; creation.com/denisovan.
67. Tomkins, J. and Bergman, J., Genomic monkey business—estimates of nearly identical human-chimp DNA similarity re-evaluated using omitted data, J. Creation 26:94–100, 2012; creation.com/human-chimp-dna-similarity-re-evaluated.
68. Demuth J.P. et al., The evolution of mammalian gene families, PLoS ONE 1(1): e85, 2006.
69. 6 million years / ~20 years per generation = only 300,000 generations.
70. Varki, A. and Altheide, T.K., Comparing the human and chimpanzee genomes: searching for needles in a haystack, Genome Research 15:1746–1758, 2005.
71. Statham, D., Heads I win, tails you lose: the power of the paradigm, Nov 2010; creation.com/fused.
72. Cohen, J., Relative differences: the myth of 1%, Science 316:1836, 2007.
73. Darwin, C., Origin of Species, 6th ed., 1872.